- Subscribe to BBC Science Focus Magazine
- Previous Issues
- Future tech
- Everyday science
- Planet Earth
- Newsletters

DNA: a timeline of discoveries
The discovery of DNA is one of our greatest scientific achievements but how did it happen?
Kath Nightingale
1869 – Friedrich Miescher discovers DNA in his preparations of white blood cells extracted from the pus in surgical bandages. He calls it ‘nuclein’.
1912-14 – William Henry Bragg and son William Lawrence Bragg lay the foundations for the field of X-ray crystallography when they realise they can infer the structure of crystals from the patterns of scattered X-rays.

1920s – Phoebus Levene discovers nucleotides – the combination of a sugar, base and phosphate group – and suggests they form short lengths of DNA called ‘tetranucleotides’.
1937 – Florence Bell arrives in William Astbury’s lab and takes the first X-ray images of DNA. Astbury makes an attempt at a structure the following year.
1944 – Oswald Avery, Colin MacLeod and Maclyn McCarty demonstrate that DNA is the material controlling inheritance.
1952 – Rosalind Franklin takes ‘Photo 51’, a highly detailed image of the ‘B’ or hydrated form of DNA. The photo is later seen by James Watson without her knowledge.

Read more about the discovery of DNA:
- How we unravelled the structure of DNA
- Photo 51: the key discovery behind the structure of DNA
- Understanding DNA: Five key scientists who unravelled the helix
- Who really discovered DNA?
1953 – James Watson and Francis Crick propose a model for the structure of the DNA molecule.
They publish the structure in the scientific journal Nature and suggest that the structure indicates DNA’s function.

1972 – DNA from two different organisms is spliced together for the first time by Paul Berg, paving the way for genetic modification and GM foods.
1996 – Dolly the sheep is born. Dolly is the first mammal cloned from a non-embryonic cell. Her DNA is identical to the sheep she was cloned from.
2003 – After £3bn and 13 years of work, the Human Genome Project is completed and the entire genome of a human being is published. Today, people can get their genome sequenced in a matter of hours for around £100.

2015 – President Barack Obama announced plans to sequence the genomes of one million US citizens to help personalise medicine and learn more about rare diseases.
Share this article

- Terms & Conditions
- Privacy policy
- Cookies policy
- Code of conduct
- Magazine subscriptions
- Manage preferences
DNA Journey series 2 — celebrity pairs, discoveries, interviews, and everything we know
In the second series of DNA Journey on ITV, more celebrities team up to discover surprising facts about their ancestors.

The second series of DNA Journey — the ITV ancestry show — sees three celebrity duos set off on a globetrotting quest to find out where their families really came from and unearth secrets from their past, all using cutting-edge DNA technology and genealogy techniques.
DNA Journey season 1 in 2019 saw showbiz pals Ant & Dec discover their family history, followed by Jamie Redknapp and Freddie Flintoff, then Amanda Holden and Alan Carr. Now it's the turn of three more star pairings to do the same. So join Dancing on Ice judges Jayne Torvill and Christoper Dean, as well as The Chase stars Anne Hegerty and Shaun Wallace, plus Coronation Street actors Maureen Lipman and Rula Lenska whose friendship takes them on a life-changing road trip to Poland.
This second season of DNA Journey is actually split into two halves, so later in 2022 the show will feature further pairings of comedian pals Rob Beckett and Romesh Ranganathan , Gavin and Stacey stars Alison Steadman and Larry Lamb , plus Joel Dommett and Tom Allen, then Good Morning Britain 's Alison Hammond and Kate Garraway.
So here's all you need to know about the second series of ITV's DNA Journey ...
DNA Journey release date
DNA Journey season 2 is a three-parter on ITV that begins Tuesday, April 5 at 9pm and runs at the same time on ITV in subsequent weeks — see our episode guide below for details. It will also become available on ITV Hub. The first episode features The Chase stars Anne Hegerty and Shaun Wallace, followed by Rula Lenska and Maureen Lipman, then Torvill and Dean. The remaining episodes of the series will be shown later in 2022.
DNA Journey — Anne Hegerty and Shaun Wallace on episode 1
The Chase's Anne Hegerty and Shaun Wallace are the first celebrity pairing to explore their family trees for this series of ITV’s DNA Journey , and it turns out to be a road trip neither of them will forget! Guided by genealogists and historians, the famous quizzers follow their bloodlines using their DNA, which takes them to Jamaica where Shaun traces his family to the early 1700s.
"I’m amazed records even went back that far," says Shaun. "It was fascinating because I also discovered I have certain traits that come from my ancestors, like an aptitude for maths. It seems DNA does carry on through the generations.’
Meanwhile, back in the UK, Anne discovers some surprising royal links and solves a long-held mystery involving her Scottish great grandmother, who was born out of wedlock. "My mother had always discouraged me from finding out anything about my ancestors, so this was a wonderful opportunity to clear a few things up," says Anne. "I also got to handle the skull of one of my distant relations. I can’t tell you any more, but it was a proud moment!"
But Anne and Shaun admit their road trip not only gave them a fascinating insight into their family histories but also cemented their friendship. "I couldn’t have chosen a better DNA partner than Anne," says Shaun. "This experience just reinforced my love and admiration for her!"
So did they pack any must-haves for the trip or agree on any traveling dos and don’ts? "No we didn’t!" admits Shaun. "Actually, the one thing I really love about the way Anne and I interact is that we always know when not to crowd each other. That’s very important. Although we were doing this journey together we made sure we had our own downtime. We always respect each other’s space and I think that’s the way our relationship thrives."
Rula Lenska and Maureen Lipman in episode 2
In the second episode of DNA Journey season 2 (Tuesday, April 12, 9pm ITV), Rula Lenska and Maureen Lipman, both of whom have had roles in Coronation Street and became close friends on the cobbles, discover some relatives they never knew existed. Extraordinary connections are uncovered as the pair journey to Poland and the north of England to find out about their families’ histories.
" knew a lot more about my maternal side than my father’s", says Rula who’s the daughter of aristocratic Polish refugees. "My mother was a countess who fled to Romania and then Yugoslavia and survived a Nazi concentration camp before arriving in England. I know far less about my father’s side so I was interested to know what surprises I might unearth."
Meanwhile Maureen, who was born in Hull, and whose father was a tailor and mother a housewife, says: "What I know about my ancestral family could be written on the side of a Smartie!"
Their voyage of discovery begins in Hull where Maureen learns about her maternal great grandfather, Victor Slimmer, a Jewish immigrant who found work in the city as a shoe maker and started a family there. Later Maureen and Rula go to Poland where, in Kazimierz, they hear some amazing news.
"I was stunned to discover that Victor was born there, the very same place where Rula’s father was born,’ says Maureen. "The more we found out, the more we realised our ancestors could have crossed paths!". Rula adds: ‘There were a series of such extraordinary coincidences. It was quite unbelievable. It was a bit like a treasure hunt. To be able to share such discoveries with Maureen was a gift.’"

Jayne Torvill and Christopher Dean in episode 3
In the last episode of DNA Journey (Tuesday, April 26, 9pm ITV), ice dance legends and Dancing On Ice judges Jayne Torvill and Christopher Dean trace their ancestral histories. As well as returning to their home city of Nottingham, where their ice-skating partnership began when they were teenagers, the Olympic gold medalists’ genealogy road trip also takes them to London and Bristol, where they discover campaigners, explorers and some sporting connections in their ancestry.
Chris says: "When I was six, I remember one day seeing my mother leaving with a suitcase and, two hours later, Betty, my step-mum turning up. My dad was the only constant. That was the day I became my own little island; my background is a mystery to me. These three people are all I know. Who else is out there that I’m related to?
Jayne says: "I know both of us were hoping we didn’t have any criminals in the family! People have often asked me if there were any sporty people in my background and where did I get my passion from. Neither of my parents were sporty, so it was interesting to find out something along those lines... My son, as he’s grown up, has done two sports – boxing and football. So it was nice to be told that some of my relatives had a connection to both those sports. When you get the full story, it’s genuinely very exciting. I was thrilled with the outcome!"

Is there a trailer for DNA Journey season 2?
No trailer for DNA Journey series 2 has been released by ITV, but we can still see the trailer for the first series below, when Ant & Dec found out about their families...
Get the What to Watch Newsletter
The latest updates, reviews and unmissable series to watch and more!

I'm a huge fan of television so I really have found the perfect job, as I've been writing about TV shows, films and interviewing major television, film and sports stars for over 25 years. I'm currently TV Content Director on What's On TV, TV Times, TV and Satellite Week magazines plus Whattowatch.com. I previously worked on Woman and Woman's Own in the 1990s. Outside of work I swim every morning, support Charlton Athletic football club and get nostalgic about TV shows Cagney & Lacey, I Claudius, Dallas and Tenko. I'm totally on top of everything good coming up too.
Mr Bates vs The Post Office lost ITV £1million despite being the biggest show in a decade — here's why
Red Eye ending explained: Who killed Shen Zhao?
The best Netflix VPN in 2024
Most Popular
- 2 Why is Law & Order: SVU not new tonight, April 25?
- 3 Why is Station 19 not new tonight, April 25?
- 4 How to watch Call Me Country: Beyoncé & Nashville's Renaissance
- 5 Clipped: release date, trailer, cast and everything we know about LA Clippers limited series
We earn a commission for products purchased through some links in this article.
First look at Strictly and Line of Duty stars in new DNA Journey series
Series five incoming.

The ITV show, which spun out of a two-part special with Ant & Dec , sees pairs of celebrities setting out on a journey to explore their family heritage and history. In some cases, they uncover stories about family members they never even knew about.
A post from Ant & Dec's production company Mitre Studios, which makes the show, tweeted a short video teasing that DNA Journey wanted to "DNAirdrop" fans four new photos.
Related: Ant & Dec announce huge career news after 25 years with ITV
As announced earlier this month, Strictly judge Motsi Mabuse and her sister Oti, a former Strictly pro who is now a judge on Dancing on Ice , will be appearing on the show together.
Meanwhile, comedians Johnny Vegas and Alex Brooker will be paired together, as will John Bishop and Downton Abbey 's Hugh Bonneville.
Related: Coronation Street co-stars discover long-lost connection on DNA Journey
The series will also feature a pair of Line of Duty actors — Neil Morrissey, who played Nigel Morton, and Adrian Dunbar, who played Ted Hastings.
Related: I'm a Celebrity hosts Ant and Dec tease "brutal" format of all-stars series
Speaking in 2020, Ant and Dec reflected on the importance of acknowledging how their friendship was tested following Ant's drink-driving arrest in 2018.
"We took the journey and then our lives both took a turn in the middle of filming and we didn't expect that to happen," said Dec at the time. "Then that became a huge learning process for us."

"We decided that we would keep it in, and talk about it, because we had to," Ant added. "It's such an honest show – if we'd have dodged it, it would have been dishonest. It's all in there, and the end result was crazy."
Since then, the show has transformed to explore the backgrounds of many celebrities. The most recent series of DNA Journey featured Rob Beckett and Romesh Ranganathan, Alison Hammond and Kate Garraway , Joel Dommett and Tom Allen, and Alison Steadman and Larry Lamb.
DNA Journey airs on ITV1 and is also available to stream on ITVX.
Best Entertainment and Tech Deals

Shop Sky deals across TV, broadband and mobile

Shop Google Pixel 7a phones

Coronation Street X Joanie - Gilroy Retro Newton And Ridley Sweatshirt

LEGO Disney and Pixar ‘Up’ House

LEGO 007 Aston Martin DB5 James Bond

Sign up for Apple TV+

Heartstopper Volume 5

Barbie The Movie doll

Sign up for Disney+

Ted Lasso x Nike: AFC Richmond home kit

The Woman in Me by Britney Spears

Jojo: Finally Home by Johannes Radebe

The Witcher wolf pendant

Barbenheimer - Barbie v Oppenheimer T-shirt

Barbenheimer T-shirt

Best PS5 deals - where to buy PS5 today?

Anker PowerCore Essential 20,000 PD Power Bank
Reporter, Digital Spy
Jacob is a freelance writer who specialises in narrative TV and film.
He graduated from the University of Roehampton with an MA in Journalism and has written for several publications since, including Gold Derby , Insider , and Screen Daily .
Jacob has covered major events in the world of film and TV, including numerous BAFTA ceremonies and the Cannes Film Festival, while he's also been an awards expert for several publications, including Korea's Arirang . His particular areas of interest include Star Wars , the MCU, the Oscars, and Hugh Grant.

.css-15yqwdi:before{top:0;width:100%;height:0.25rem;content:'';position:absolute;background-image:linear-gradient(to right,#51B3E0,#51B3E0 2.5rem,#E5ADAE 2.5rem,#E5ADAE 5rem,#E5E54F 5rem,#E5E54F 7.5rem,black 7.5rem,black);} Reality TV

Drag Race announces All Stars 9 release date

Strictly's Kai Widdrington rejected job offer

Gogglebox's Jenny confused by "dark" dramas

Taskmaster star explains Dracula costume choice

MAFS star Tamara Djordjevic shares new career move

TOWIE's Amber hits back at claims she's quit show

BGT judge Bruno reveals new act causes huge mess

Ekin-Su apologises as she explains accent change

Gogglebox's Ellie Warner shares baby bump photo

BGT's Amanda Holden reveals who she wants to win

The One Show host thanks NHS after son's surgery
Trending articles

Raising a glass to Portugal’s best wine regions

As of writing, our video campaign has been viewed more than 28 million times on our Facebook page , viewed more than five million times on our YouTube channel , shared more than 600,000 times globally and commented on by thousands of people from all over the world.
169,631 people entered our The DNA Journey competition with the hope of winning their very own DNA Journey (please note: the competition is now closed for entries) .
This makes us really happy! We’re proud to have created a campaign with a message of diversity which resonates with so many people.
Along with an overwhelming number of positive reactions, The DNA Journey film has prompted a number of questions around the making of the film and the participants. We will answer those questions here.
What is the purpose of The DNA Journey?
The purpose of The DNA Journey campaign is to show that we, as people, have more things uniting us than dividing us. The DNA Journey is part of momondo’s overall vision of a more open and tolerant world. You can read more about momondo’s vision and ongoing activities here: letsopenourworld.com .
How were the participants found?
As is the case with many campaign films, we employed casting agencies to help us find participants. Specifically, we used two agencies. These two agencies sourced participants via their extras databases, their own networks and via online forums. In the process of selecting the participants, momondo was presented with their ethnicity and family history only.
The casting agencies filmed 67 people talking about themselves and where they come from for 10 minutes each. After this, they were asked to take a saliva DNA test. Based on these results, together with the participants’ personal stories, we selected 16 for the shoot in Copenhagen. The criteria we looked at were their ancestry, their perception of themselves and the world, and if there was a surprise element in their DNA results.
Are there actors in the video?
The participants of The DNA Journey appear in their own name and receive their own DNA results. Neither their occupation nor their educational background had any bearing upon their selection.
Participants came from all walks of life and all kinds of occupations. Examples of the participants’ occupations are: secretary, dog trainer, actor, account manager and model. We did not carry out specific research into what kind of profession the participants had – or have had – as they would be appearing as themselves.
However, because of the great interest in the participants’ possible acting experience we have since investigated how many have experience acting or have appeared as extras before. This applies to 10 of the participants. The only professional actress purposely cast was the role of the female interviewer. The background audience was bolstered with extras whom we did not DNA test.
Were the film’s participants told how to react to their DNA tests?
The participants in the film were not cast to act, and what they say in the film are their own words and thoughts. They were interviewed about their personal relationship to their ancestry and nationality, and later shown the result of the DNA analysis that was made a few weeks earlier.
Before the reveal of the DNA results, the contestants were very excited about their results and we talked with them about the fact that they were welcome to express this in the film. The participants were not directed individually in how to react or what to say about their DNA results.
Did the participants receive payment for their appearance?
As is normal practice in the production of an advertisement, participants were paid for both their appearance and rights.
How was the advertisement shot?
The campaign film was shot in a music venue, Vega, in Copenhagen from April 6 th to April 8 th 2016. While an intertitle in the film states, “Two weeks later”, all of the participants carried out their DNA test before the shoot. This is a modification we made for the sake of storytelling. Similarly, the spitting scenes were shot when the entire crew was together in Copenhagen for logistical reasons. During the shoot, participants were first interviewed about their views on their own nationality and other nations, and then presented with the results of their DNA test.
Were there any retakes in the film?
Yes. When a campaign film is shot, there can be multiple reasons for retakes, such as problems with the sound, an unclear image, people mumbling or the lighting being wrong. The important thing for us was to capture the spontaneous reactions when participants saw their DNA results for the first time. The participants only opened the envelope once and the film contains the reactions from that take. This is also why we used four cameras to ensure that we captured the reaction on film.
Is the story about two participants being related real?
Yes, the story is real and they were both overwhelmed when they found each other. We think it is a good story and they both shared it with their families after the shoot. The two participants are distant cousins. When you test your DNA with AncestryDNA, our partner for this campaign, you can check whether or not there are any distant cousins registered in AncestryDNA’s database. It was a pure coincidence that two out of the 67 people tested were related.
Who conducted the DNA tests in the film?
AncestryDNA carried out the tests. In the test you learn about your DNA based on 26 regions worldwide. AncestryDNA gives ethnicity estimates that map back to broad geographical regions, often including one or more countries.
AncestryDNA was able to provide each participant with a more detailed DNA map than the average taker of their DNA test, because the participant selection process had provided them with a greater understanding of each participant’s family history, surname and ancestral background.
How have the participants felt since the film was shot?
Many people have asked what reactions the participants have had since the shoot. Here are three participants’ testimonials.
‘Thank you so much for the amazing opportunity to be a part of your project. It was one of the most incredible experiences of my life. I am so grateful to have lived that experience, grateful for the way it changed me and how it is shaping my work as an artist today. Grateful for the journey into myself and for seeing others uncovering their beautiful journeys while carrying a bit of my own. I feel invincible, ageless and ready to face what the future holds.’
‘It was a profoundly emotional experience, and made me question who I am and who I thought I was. My family and friends were inspired by my journey, and loved the idea behind the campaign! Many of them are now desperate to undergo their own tests to discover their origins.’
‘I feel eager, impatient, excited, motivated, grateful, surprised, overwhelmed and filled with beautiful energy after the experience we’ve lived together in the studio.’
If you have any more questions to the film or its purpose, you’re welcome to write to us on Facebook or [email protected] .

Let’s open our world: Exploring cultural diversity with The DNA Journey
REVEALED: Our DNA Journey American prizewinner
Let’s open our world: an interview with our DNA Journey grand prizewinner
Frommer’s deems momondo best airfare search site for 2024

10 eco travel trends to look out for in 2020
- My Basket 0
paternity testing
- Paternity Test - Who's The Dad
- Prenatal Non-Invasive Paternity Test - Who's the Dad Pre-birth
Rapid DNA Paternity testing...

extended family dna testing
- Home Maternity Test - Who's the Mum?
- Sibling Testing
- Aunt & Uncle Testing
- Grandparent Testing
- Identical Twin Testing
The most advanced DNA Testing on the market...

immigration dna testing
- Immigration Paternity Test - Who's The Dad
- Immigration Maternity Test - Who's The Mum
- Immigration Sibling Testing
- Global Clinic Locations
Offering UKBA, Embassy Certificated Immigration DNA Testing in over 200 countries...
.jpg "the journey of dna")
ancestry dna testing
- Family Ancestry
- Fatherline Ancestry
- Motherline Ancestry
Discover your ancestry with the world's most advanced testing services...

drug & alcohol testing
- Hair Drug Testing
- Hair Alcohol Testing
- Legal Highs & Designer Drugs
- Expert Review of Your Drug & Alcohol Tests
Determine the pattern of drug and alcohol use...
.jpg "the journey of dna")
about dna worldwide
Latest blog posts.

DNA shows there is no such thing as a separate United Kingdom

Winner Mendip Business of the Year 2016
- Why Choose Us
- Testimonials
The History of DNA Timeline
View the slide
1859 - Charles Darwin publishes The Origin of Species
In 1859, Charles Darwin published The Origin of Species , changing the way many people viewed the world forever.
In 1831, Darwin had joined a five year scientific expedition. During his time away was influenced by Lyell's suggestion that fossils found in rocks were evidence of animals that had lived millions of years ago. The breakthrough came when he noted that the Galapagos Islands each supported its own variety of finch, which were closely related but had slight differences that seemed to have adapted in response to their individual environments.
On his return to England, Darwin proposed a theory of evolution occurring by the process of natural selection, which he then worked on over the following 20 years. The Origin of Species was the culmination of these efforts and argued that the living things best suited to their environment are more likely to survive, reproduce and pass on their characteristics to future generations. This led to a species gradually changing over time. Whilst his study contained some truth many areas such as the link between animal and human evolution are being shown to be untrue through new discoveries of ancient ancestors.
The book was extremely controversial, as it challenged the dominant view of the period that many people literally took that God had created the world in seven days. It also suggested that people were animals and might have evolved from apes this part of his work has been shown to be inaccurate. To Ponder; One must simply consider the fact that through thousands of years of evolution animals have the highest respect for their body yet people do not respect their bodies. The cheetah will go hungry rather than push itself beyond the point it can recover. If people had evolved from animals over millions of years the innate respect for their body would still be here today.
1866 - Gregor Mendel discovers the basic principles of genetics
In 1866, an unknown Augustinian monk was the first person to shed light on the way in which characteristics are passed down the generations . Today, he is widely considered to be the father of genetics. However, he enjoyed no such notoriety during his lifetime, with his discoveries largely passing the scientific community by. In fact, he was so ahead of the game that it took three decades for his paper to be taken seriously.
Between 1856 and 1863 Mendel conducted experiments on pea plants, attempting to crossbreed "true" lines in specific combinations. He identified seven characteristics: plant height, pod shape and colour, seed shape and colour, and flower position and colour.
He found that when a yellow pea plant and a green pea plant were bred together their offspring was always yellow. However, in the next generation of plants, the green peas returned in a ratio of 3:1.
Mendel coined the terms 'recessive' and 'dominant' in relation to traits, in order to explain this phenomenon. So, in the previous example, the green trait was recessive and the yellow trait was dominant.
In his 1866 published paper, Mendel described the action of 'invisible' factors in providing for visible traits in predictable ways. We now know that the 'invisible' traits he had identified were genes.
1869 - Friedrich Miescher identifies "nuclein"
In 1869, Swiss physiological chemist Friedrich Miescher first identified what he called "nuclein" in the nuclei of human white blood cells, which we know today as deoxyribonucleic acid (DNA).
Miescher's original plan had been to isolate and characterise the protein components of white blood cells. To do this, he had made arrangements for a local surgical clinic to send him pus-saturated bandages, which he planned to wash out before filtering the white blood cells and extracting their various proteins.
However, during the process, he came across a substance that had unusual chemical properties unlike the proteins he was searching for, with very high phosphorous content and a resistance to protein digestion.
Miescher quickly realised that he had discovered a new substance and sensed the importance of his findings. Despite this, it took more than 50 years for the wider scientific community to appreciate his work.
1900s - The Eugenics Movement
In the history of DNA, the Eugenics movement is a notably dark chapter, which highlights the lack of understanding regarding the new discovery at the time. The term 'eugenics' was first used around 1883 to refer to the "science" of heredity and good breeding .
In 1900, Mendel's theories, which had found a regular statistical pattern for features like height and colour, were rediscovered. In the frenzy of research that followed, one line of thought branched off into social theory and developed into eugenics.
This was an immensely popular movement in the first quarter of the 20th century and was presented as a mathematical science, which could predict the traits and characteristics of human beings.
The darker side of the movement arose when researchers became interested in controlling the breeding of human beings, so that only the people with the best genes could reproduce and improve the species. It was often used as a sort of 'scientific' racism, to convince people that certain 'racial stock' was superior to others in terms of cleanliness, intelligence etc. It shows the dangers that come with practicing science without a true respect for humanity as a whole.
Many people could see that the discipline was riddled with inaccuracies, assumptions and inconsistencies, as well as encouraging discrimination and racial hatred. However, in 1924 it gained political backing when the Immigration Act was passed by a majority in the U.S. House and Senate. The Act introduced strict quotas on immigration from countries believed by eugenicists to have 'inferior' stock such as Southern Europe and Asia. When political gain and convenient science combine forces we are left even further from truth and a society that respects those within in. This is not too dissimilar from the tobacco industries of the 80’s and the sugar industries of the current decade.
With continued scientific research and the introduction of behaviourism in 1913, the popularity of eugenics finally began to fall. The horrors of institutionalized eugenics in Nazi Germany which came to light after the 2nd World War completely extinguished what was left of the movement.
1900 – Mendel's theories are rediscovered by researchers
In 1900, 16 years after his death, Gregor Mendel's pea plant research finally made its way into the wider scientific community.
The Dutch botanist and geneticist Hugo de Vries, German botanist and geneticist Carl Erich Correns and Austrian botanist Erich Tschermak von Seysenegg all independently rediscovered Mendel's work and reported results of hybridization experiments similar to his findings.
In Britain, biologist William Bateson became a leading champion of Mendel's theories and gathered around him an enthusiastic group of followers. Known as ‘Mendelians’, the supporters initially clashed with Darwinians (supporters of Charles Darwin's theories). At the time, evolution was believed to be based on the selection of small, blending variations whereas Mendel's variations clearly did not blend.
It took three decades for Mendelian theory to be sufficiently understood and to find its place within evolutionary theory.
1902 - Sir Archibald Edward Garrod is the first to associate Mendel's theories with a human disease
In 1902, Sir Archibald Edward Garrod became the first person to associate Mendel's theories with a human disease . Garrod had studied medicine at Oxford University before following in his father's footsteps and becoming a physician.
Whilst studying the human disorder alkaptonuria, he collected family history information from his patients. Through discussions with Mendelian advocate William Bateson, he concluded that alkaptonuria was a recessive disorder and, in 1902, he published The Incidence of Alkaptonuria: A Study in Chemical Individuality. This was the first published account of recessive inheritance in humans.
It was also the first time that a genetic disorder had been attributed to "inborn errors of metabolism", which referred to his belief that certain diseases were the result of errors or missing steps in the body's chemical pathways. These discoveries were some of the first milestones in scientists developing an understanding of the molecular basis of inheritance.
1944 - Oswald Avery identifies DNA as the 'transforming principle'
By the 1940s, scientists understanding of the principles of inheritance had moved on considerably - genes were known to be the discrete units of heredity, as well as generating the enzymes which controlled metabolic functions. However, it wasn't until 1944 that deoxyribonucleic acid (DNA) was identified as the 'transforming principle' .
The man who made the breakthrough was Oswald Avery, an immunochemist at the Hospital of the Rockefeller Institute for Medical Research. Avery had worked for many years with the bacterium responsible for pneumonia, pneumococcus, and had discovered that if a live but harmless form of pneumococcus was mixed with an inert but lethal form, the harmless bacteria would soon become deadly.
Determined to find out which substance was responsible for the transformation, he combined forces with Colin MacLeod and Maclyn McCarty and began to purify twenty gallons of bacteria. He soon noted that the substance did not seem to be a protein or carbohydrate but rather a nucleic acid, and with further analysis, it was revealed to be DNA.
In 1944, after much deliberation, Avery and his colleagues published a paper in the Journal of Experimental Medicine, in which they outlined the nature of DNA as the 'transforming principle'. Although the paper was not widely read by geneticists at the time, it did inspire further research, paving the way for one of the biggest discoveries of the 20th century.
1950 - Erwin Chargaff discovers that DNA composition is species specific
In 1944, scientist Erwin Chargaff had read Oswald Avery's scientific paper , which identified DNA as the substance responsible for heredity. The paper had a huge impact on Chargaff and changed the future course of his career. He later recollected, “Avery gave us the first text of a new language, or rather he showed us where to look for it. I resolved to search for this text. Consequently, I decided to relinquish all that we had been working on or to bring it to a quick conclusion”.
Chargaff was determined to begin work on the chemistry of nucleic acids. His first move was to devise a method of analysing the nitrogenous components and sugars of DNA from different species.
He subsequently submitted two papers to the Journal of Biological Chemistry (JBC) detailing the complete qualitative analysis of a number of DNA preparations. Despite the significance of the paper’s findings, the JBC was initially reluctant to publish it, illustrating the ignorance about nucleic acids amongst elite scientists at the time.
Chargaff continued to improve his research methods and was eventually able to rapidly analyse DNA from a wide range of species. In 1950, he summarised his two major findings regarding the chemistry of nucleic acids: first, that in any double-stranded DNA, the number of guanine units is equal to the number of cytosine units and the number of adenine units is equal to the number of thymine units, and second that the composition of DNA varies between species. These discoveries are now known as 'Chargaff's Rules'.
1952 - Rosalind Franklin photographs crystallized DNA fibres
Rosalind Franklin was born in London in 1920 and conducted a large portion of the research which eventually led to the understanding of the structure of DNA - a major achievement at a time when only men were allowed in some universities' dining rooms.
After achieving a doctorate in physical chemistry from Cambridge University in 1945, she spent three years at the Laboratoire Central des Services Chimiques de L'Etat in Paris, learning the X-Ray diffraction techniques that would make her name. Then, in 1951, she returned to London to work as a research associate in John Randall's laboratory at King's College.
Franklin's role was to set up and improve the X-ray crystallography unit at King's College. She worked with the scientist Maurice Wilkins, and a student, Raymond Gosling, and was able to produce two sets of high-resolution photographs of DNA fibres. Using the photographs, she calculated the dimensions of the strands and also deduced that the phosphates were on the outside of what was probably a helical structure.
Franklin's photographs were described as, "the most beautiful X-ray photographs of any substance ever taken" by J. D. Bernal, and between 1951 and 1953 her research came close to discovering the structure of DNA. Unfortunately, she was ultimately beaten to the post by Thomas Watson and Frances Crick.
The above image shows the original samples of DNA which were given to Maurice Wilkins by Swiss biochemist Rudolf Signer. PhD student Raymond Gosling then used the samples to produce the first crystals of DNA and, with Rosalind Franklin, used them for the next generation of X-ray images.
1953 - James Watson and Francis Crick discover the double helix structure of DNA
In 1951, James Watson visited Cambridge University and happened to meet Francis Crick. Despite an age difference of 12 years, the pair immediately hit it off and Watson remained at the university to study the structure of DNA at Cavendish Laboratory.
Using available X-ray data and model building, they were able to solve the puzzle that had baffled scientists for decades. They published the now-famous paper in Nature in April, 1953 and in 1962 they were awarded the Nobel Prize for Physiology or Medicine along with Maurice Wilkins.
Despite the fact that her photographs had been critical to Watson and Crick's solution, Rosalind Franklin was not honoured, as only three scientists could share the prize. She died in 1958, after a short battle with cancer.
1953 - George Gamow and the “RNA Tie Club”
Following Watson and Crick's discovery, scientists entered a period of frenzy, in which they rushed to be the first to decipher the genetic code. Theoretical physicist and astronomer George Gamow decided to make the race more interesting - he created an exclusive club known as the “RNA Tie Club”, in which each member would put forward their ideas about how nucleotide bases were transformed into proteins by the body's cells.
He handpicked 20 members - one for each amino acid - and they each wore a tie carrying the symbol of their allocated amino acid. Ironically, the man who was to discover the genetic code, Marshall Nirenberg, was not a member.
1959 - An additional copy of chromosome 21 linked to Down's syndrome
Today, scientists routinely use our growing understanding of genetics for disease diagnosis and prognosis. However, it took decades for cytogenetics (the study of chromosomes) to be recognised as a medical discipline.
Cytogenetics first had a major impact on disease diagnosis in 1959, when an additional copy of chromosome 21 was linked to Down's syndrome. In the late 1960s and early 70s, stains such as Giemsa were introduced, which bind to chromosomes in a non-uniform fashion, creating bands of light and dark areas. The invention transformed the discipline, making it possible to identify individual chromosomes, as well as sections within chromosomes, and formed the basis of early clinical genetic diagnosis.
1965 - Marshall Nirenberg is the first person to sequence the bases in each codon
In 1957, Marshall Nirenberg arrived at the National Institute of Health as a postdoctoral fellow in Dr. DeWitt Stetten, Jr.'s laboratory. He decided to focus his research on nucleic acids and protein synthesis in the hope of cracking 'life's code'.
The following few years were taken up with experiments, as Nirenberg tried to show that RNA could trigger protein synthesis. By 1960, Nirenberg and his post-doctoral fellow, Heinrich Matthaei were well on the way to solving the coding problem.
Nirenberg and Matthaei ground up E.Coli bacteria cells, in order to rupture their walls and release the cytoplasm, which they then used in their experiments. These experiments used 20 test tubes, each filled with a different amino acid - the scientists wanted to know which amino acid would be incorporated into a protein after the addition of a particular type of synthetic RNA.
In 1961, the pair performed an experiment which showed that a chain of the repeating bases uracil forced a protein chain made of one repeating amino acid, phenylalanine. This was a breakthrough experiment which proved that the code could be broken.
Nirenberg and Matthaei conducted further experiments with other strands of synthetic RNA, before preparing papers for publication. However, there was still much work to do - the scientists now needed to determine which bases made up each codon, as well as the sequence of bases within the codons.
Around the same time, Nobel laureate Severo Ochoa was also working on the coding problem. This sparked intense competition between the laboratories, as the two scientists raced to be the first to the finish line. In the hope of ensuring that the first NIH scientist won the Nobel Prize, Nirenberg's colleagues put their own work on hold to help him achieve his goal.
Finally, in 1965, Nirenberg became the first person to sequence the code. In 1968, his efforts were rewarded when he, Robert W. Holley and Har Gobind Khorana were jointly awarded the Nobel Prize.
1977 - Frederick Sanger develops rapid DNA sequencing techniques
By the early 1970s, molecular biologists had made incredible advances . They could now decipher the genetic code and spell out the sequence of amino acids in proteins. However, further developments in the field were being held back by the inability to easily read the precise nucleotide sequences of DNA.
In 1943, Cambridge graduate Frederick Sanger started working for A. C. Chibnall , identifying the free amino groups in insulin. Through this work, he became the first person to order the amino acids and obtain a protein sequence, for which he later won a Nobel Prize. He deduced that if proteins were ordered molecules, then the DNA that makes them must have an order as well.
In 1962, Sanger moved with the Medical Research Council to the Laboratory of Molecular Biology in Cambridge, where DNA sequencing became a natural extension of his work with proteins. He initially began working on sequencing RNA, as it was smaller, but these techniques were soon applicable to DNA and eventually became the dideoxy method used in sequencing reactions today.
For his breakthrough in rapid sequencing techniques, Sanger earned a second Nobel Prize for Chemistry in 1980, which he shared with Walter Gilbert and Paul Berg.
1983 - Huntington's disease is the first mapped genetic disease
HD is a rare, progressive neurodegenerative disease which usually manifests itself between 30 and 45 years of age . It's characterised by a loss of motor control, jerky movements, psychiatric symptoms, dementia, altered personality and a decline in cognitive function. As the disease is adult onset, many people have already had children before they are diagnosed and have passed the mutant gene onto the next generation.
In 1983, a genetic marker linked to HD was found on Chromosome 4 , making it the first genetic disease to be mapped using DNA polymorphisms. However, the gene was not finally isolated until 1993.
1990 - The first gene found to be associated with increased susceptibility to familial breast and ovarian cancer is identified
In 1990, the first gene to be associated with increased susceptibility to familial breast and ovarian cancer was identified. Scientists had performed DNA linkage studies on large families who showed characteristics related to hereditary breast ovarian cancer (HBOC) syndrome.
They named the gene they identified, which was located on chromosome 17, BRCA1. However, it was clear that not all breast cancer families were linked to BRCA1, and, with continued research, a second gene BRCA2 was located on chromosome 13.
Everyone has 2 copies of both BRCA1 and BRCA2, which are tumour suppressor genes. If a person has 1 altered copy of either gene it can lead to an accumulation of mutations, which can then lead to tumour formation.
1990 - The Human Genome Project begins
In 1988, The National Research Council recommended a program to map the human genome. The Human Genome Project officially started in 1990 , with the U.S. Department of Energy (DOE) and the National Institutes of Health (NIH) publishing a plan for the first five years of the anticipated 15 year project.
Many organisations had a long-standing interest in mapping the human genome for the sake of advancing medicine, but also for purposes such as the detection of mutations that nuclear radiation might cause.
The project's goals included: mapping the human genome and determining all 3.2 billion letters in it, mapping and sequencing the genomes of other organisms, if it would be useful to the study of biology, developing technology for the purpose of analysing DNA and studying the social, ethical and legal implications of genome research.
1995 - Haemophilus Influenzae is the first bacterium genome sequenced
In 1995, to demonstrate the new strategy of "shotgun" sequencing, J. Craig Venter and colleagues published the first completely sequenced genome of a self-replicating, free-living organism - Haemophilus Influenzae.
Known as H.flu, Haemophilus Influenzae is a bacterium that can cause meningitis and ear and respiratory infections in children. Prior to this breakthrough, scientists had only managed to sequence the genome of a few viruses, which are around ten times shorter than that of H.flu.
The project took around a year and was a remarkable achievement. Its success proved that the random shotgun technique could be applied to whole genomes quickly and accurately, paving the way for future discoveries.
1996 - Dolly the sheep is cloned
The world famous Dolly the sheep was the first mammal to be cloned from an adult cell . The feat was ground-breaking - whilst animals such as cows had previously been cloned from embryo cells, Dolly demonstrated that even when DNA had specialised, it could still be used to create an entire organism.
Dolly was created by scientists working at the Roslin Institute in Scotland, from the udder cell of a six-year-old Finn Dorset white sheep. By altering the growth medium, the scientists found a way to 'reprogram' the cell, which was then injected into an unfertilised egg that had had its nucleus removed. The egg was then cultured to reach the embryo stage, before being implanted into a surrogate mother.
Cloning from adult cells is a difficult process and out of 277 attempts, Dolly was the only lamb to survive. She went on to live a pampered existence at the Roslin Institute and was able to produce normal offspring. Following her death, she was stuffed and put on display, as can be seen in the accompanying image.
1996 - 'Bermuda Principles' established
In 1996, the leaders of the Human Genome Project met in Bermuda and agreed that genome sequence data should be made freely available in the public domain within 24 hours of generation.
Known as the 'Bermuda Principles', the agreement was designed to ensure that sequence information led as rapidly as possible to advances in healthcare and research.
In order to co-ordinate the process, it was also agreed that large-scale sequencing centres would inform the Human Genome Organisation (HUGO) of any intentions to sequence particular regions of the genome. HUGO would then place this information on their website and direct visitors to the specific centres for more detailed information regarding the current status of sequencing.
1999 - First human chromosome is decoded
In 1999, an international team of researchers reached a major milestone when they unravelled for the first time the full genetic code of a human chromosome . The chromosome in question was chromosome 22, which contained 33.5 million "letters," or chemical components.
At the time, the sequence was the longest continuous stretch of DNA ever deciphered and assembled. However, it was only the first deciphered chapter of the human genetic instruction book - the rest was still to come.
2000 – Genetic code of the fruit fly is decoded
In March 2000, scientists from a number of laboratories successfully decoded the genetic makeup of the fruit fly . The collaborative effort had major implications for the sequencing of the human genome, as fly cell biology and development has much in common with mammals .
During their research, the scientists discovered that every fruit fly cell contains 13,601 genes, making it by far the most complex organism decoded at the time. However, by contrast, human cells contain 70,000 genes. Whilst the Human Genome Project still had a long way to go to achieve its ultimate objective, this was an important milestone along the way.
2002 – Mouse is the first mammal to have its genome decoded
In 2002, scientists took their next big step and decoded the genome of the first mammal – the mouse. The achievement allowed them to compare, for the first time, the human genome with that of another mammal.
Amazingly, it emerged that 90% of the mouse's genome could be aligned with the corresponding regions on the human genome. Both the mouse and human genome also contained around 30,000 protein-coding genes. These discoveries highlighted for the first time just how closely mammalian species were genetically related.
2003 – The Human Genome Project is completed
History was made in 2003 when the Human Genome Project was finally completed . The international research project could be described as the greatest journey ever made – albeit an inwards one.
Scientists had achieved a high-quality sequence of the entire human genome. In 2001, the Human Genome Project had published a 'rough draft' of the human genome, which included a 90% sequence of all three billion base pairs .
Following this, scientists pursued the second stage of the project – the finishing phase. During this time, researchers filled in the gaps and resolved DNA features in ambiguous areas until they had completed 99% of the human genome in final form.
This final form contains 2.85 billion nucleotides, with a predicted error rate of just 1 event in every 100,000 bases sequenced. Surprises included the relatively small number of protein-encoding genes (between 20,000 and 25,000) and that there were similar genes with the same functions present in different species.
When you consider that less than 200 years previously, pioneers like Charles Darwin were only beginning to suspect characteristics could be inherited, it's mind-boggling what scientists have managed to achieve.
2013 – DNA Worldwide and Eurofins Forensic discover identical twins have differences in their genetic makeup
In 2013, DNA Worldwide and their laboratory partners Eurofins Forensic were the first in the world to prove that twins have differences in their genetic make-up .
Before this discovery, it was believed that monozygotic twins are 100% genetically identical, and that DNA testing could not be used in criminal or paternity cases involving identical twins, as it was impossible to tell them apart.
However, the team at DNA Worldwide decided to test this theory by combining Forensic DNA profiling and Genomic Sequencing. The scientists applied ultra-deep, next generation sequencing and combined this with bioinformatics, sequencing the DNA from sperm samples of two twins and a blood sample of the child of one twin. The Bioinformatic analysis identified five differences (mutations), called Single Nucleotide Polymorphisms (SNPs) present in the twin who was a father and his child, but not in the twin uncle.
These SNP differences were confirmed by Sanger sequencing, and gave experimental evidence for the hypothesis that rare mutations in the genes will occur early, after or before the human blastocyst has split into two and that these mutations will be carried throughout the lifespan.
These differences and the methods developed by DNA Worldwide laboratory provided a solution to the problems facing complex paternity and forensic cases involving identical twins.
2014 – Further Breakthroughs
Throughout 2014 the world's scientists have continued to develop their understanding of DNA. Researchers announced in May that they had successfully created an organism with an expanded artificial genetic code . This success could eventually lead to the creation of organisms that can produce medicines or industrial products organically.
There have also been breakthroughs in the medical field; the largest ever study into the genetic basis of mental illness has found more than 100 genes that play a role in the development of schizophrenia . These findings have the potential to kick-start the production of new drugs to treat this not uncommon psychiatric illness.
Geneticists have also made progress in the breakthrough field of epigenetics (the study of changes in organisms caused by altered gene expression). By studying pairs of identical twins, researchers in Sweden have found that changes in the expression of genes involved in inflammation, fat and glucose metabolism could be behind the development of Type 2 Diabetes .
Future – Epigenetics, personalised medicine and greater individual responsibility
So, what does the future hold for our understanding of genetics? In recent decades, epigenetics has been a ground-breaking area of developing research. Essentially, the term epigenetics means 'on genetics' and refers to the biological markers which influence what 'comes out' of the DNA sequence.
Research has found that there are a huge number of these molecular mechanisms affecting the activity of our genes. Incredibly, it has emerged that our life experiences and choices can change the activity of these mechanisms, resulting in changes in gene expression. Even more fascinating is that these changes in gene expression can be inherited, meaning that the life experiences of your ancestors can fundamentally influence your biological make-up.
These discoveries are likely to have a dramatic impact on the future of the healthcare system. We're beginning to understand that the choices we make can have a long-term impact on our health and can cause genetic level change, which could even impact future generations. Individual responsibility for our lifestyle choices is therefore more important than ever before.
Another likely future development is the increased use of personalised medicines. Many genetic diseases are caused by mutated genes, but these can differ from one person to the next. By identifying these combinations, medicines can be tailored to the individual, providing the best possible treatment.
DNA Journey
In episode one of this two-part special, Ant and Dec take on their most personal journey yet, uncovering their family histories using a combination of DNA and genealogy.

- S Subtitles
- Documentaries & Lifestyle
Famous faces bond over their remarkable family secrets in this exploratory documentary. Watch them find relatives they never knew existed.
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- NEWS & VIEWS FORUM
- 30 January 2024
The journey to understand previously unknown microbial genes
- Jakob Wirbel ORCID: http://orcid.org/0000-0002-4073-3562 0 ,
- Ami S. Bhatt ORCID: http://orcid.org/0000-0001-8099-2975 1 &
- Alexander J. Probst ORCID: http://orcid.org/0000-0002-9392-6544 2
Jakob Wirbel is in the Department of Medicine, Division of Hematology, Stanford University School of Medicine, Stanford, California 94305, USA.
You can also search for this author in PubMed Google Scholar
Ami S. Bhatt is in the Department of Medicine, Division of Hematology, Stanford University School of Medicine, Stanford, California 94305, USA, and in the Department of Genetics, Stanford University School of Medicine.
Alexander J. Probst is in the Research Center One Health Ruhr, University Alliance Ruhr, Department of Chemistry at University of Duisburg-Essen, Essen, 45141, Germany.
You have full access to this article via your institution.
THE TOPIC IN BRIEF
• Some aspects of microbiology remain mysterious because of a lack of information about the identity and role of many microbial genes and proteins.
• The ability to obtain and analyse microbial sequences at scale and across species, including those that cannot be grown under laboratory conditions, are providing insights and data to explore.
• Writing in Nature , Rodríguez del Río et al . 1 report their analysis of 149,842 bacterial genomes sampled from a variety of habitats in the wild.
• The data were used to select sequences to generate a catalogue of 404,085 previously unknown gene families that could be prioritized for further study.
• The investigation of these previously unknown genes could lead to new clinical tools or offer fresh perspectives about how microorganisms evolved to survive in their natural environments.
JAKOB WIRBEL & AMI S. BHATT: Bringing structure and context to gene mysteries
The function of most microbial genes is unknown. Some of this microbial ‘dark matter’ might encode previously unknown types of enzyme or classes of antibiotic. As ever more genes of unknown function are discovered through sequencing of DNA from mixtures of multiple genomes, termed metagenomic sequencing, the difficulty of experimentally characterizing these enigmatic genes has led to a focus on computationally predicting their function 2 . Two publications in Nature , one by Rodríguez del Río et al . 1 , and one by Pavlopoulos et al . 3 published last October, tackle this challenge by cleverly leveraging advances in clustering algorithms (computational tools that group genes on the basis of similarities in amino-acid sequence) and protein-structure prediction tools 4 such as AlphaFold.
Read the paper: Functional and evolutionary significance of unknown genes from uncultivated taxa
Despite distinct technical approaches, the core strategy used by Pavlopoulos et al . and Rodríguez del Río et al . was similar. Both clustered hundreds of millions of protein sequences from metagenomic data sets into previously unknown protein families. Rodríguez del Río and colleagues filtered their data to examine genes only from prokaryotes (organisms whose cells lack a nucleus), whereas Pavlopoulos et al . used data that also included sequences from eukaryotes (organisms whose cells have a nucleus) and viruses.
With these catalogues of previously unknown families at hand, both teams set out to predict the function of their newly described families, capitalizing on genomic-context analysis, which involves examining adjacent genes for clues about function, as well as harnessing breakthroughs in methods to predict protein structures. In prokaryotic genomes, genes involved in the same pathway are often present close to one other. Genomic-context analysis, which proposes ‘guilt by association’, has been used effectively to predict previously unknown antiviral defence systems used by bacteria 5 . The second approach, comparing predicted protein structures to find similar (homologous) proteins, is more sensitive than simply comparing amino-acid sequences alone 6 . Both teams predicted structures for their protein families and compared them with databases of known structures, thereby generating informed predictions about the function of some of these enigmatic proteins.
The sheer scale and computational investment involved in these efforts, which yielded hundreds of thousands of newly discovered protein families (Fig. 1), is impressive. Yet, the number of previously unknown genes that have a functional prediction still remains relatively small. In both publications, only around 15% of the previously unknown protein families could be annotated on the basis of structural similarity; genomic-context analysis enabled functions to be proposed for 7.4% of families in Pavlopoulos et al . and 13% in Rodríguez del Río and co-workers. In addition, some assigned functional categories (such as ‘ribosome’) lack detailed specificity and this might obscure the precise role of these genes. Ultimately, the reliability of these predictions will have to be determined experimentally. Indeed, Rodríguez del Río et al. took the first step towards this objective by experimentally verifying the annotation for two of their predicted families.

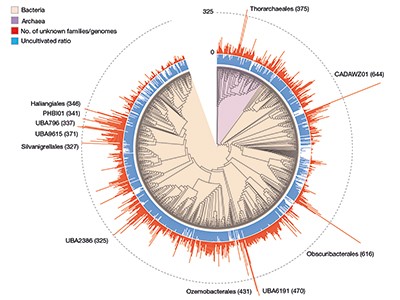
Figure 1 | Previously unknown microbial gene families. The large-scale analysis of DNA sequences captured from microbial samples as reported by Rodríguez del Río et al . 1 and by Pavlopoulos et al . 3 has revealed hundreds of thousands of previously unknown gene families. These data — which were gathered from microbes in the wild and across different habitats, and include species that have not been cultivated in the laboratory — provide a starting point for gaining insights into unexplored aspects of the biology of bacterial and archaeal microorganisms. Figure adapted from Fig. 3a of ref. 1.
By delving deeper into the microbial dark matter, these two studies unlock a wealth of previously hidden knowledge, paving the way for future discoveries in diverse fields from medicine to biotechnology. Follow-up experiments might include the study of protein families with completely new protein folds, possibly revealing unexplored biological functions. Similarly, synapomorphic genes — corresponding to protein families that are specific to a group of organisms sharing a common ancestor but absent in others — might hold clues to key evolutionary processes. With further refinement and validation, these computational approaches offer a powerful tool for unlocking the functional secrets of the unseen microbial world.
ALEXANDER J. PROBST: Microbial sequences reveal ecology and evolution
Genes are the ultimate source of all biological information on Earth, from human eye colour to the cell shape of microorganisms. The proteins they encode can be grouped using bioinformatics into families, usually with shared functionality. The ensemble of all known proteins in databases is continuously expanding as genomes are sequenced and the functions of the encoded proteins are predicted. The greatest fraction of biological functional diversity on our planet is attributed to microbial proteins. With the advent of sequencing of mixed microbial genomes from the environment (an approach that explores multiple genomes and is called metagenomics 7 ), the increase in the rate at which data are being added to genome and protein databases is striking. However, the functional capacity of most protein families is unknown and part of the microbial dark matter.
Tracking humans and microbes
Rodríguez del Río and colleagues’ work, as well as the study by Pavlopoulos et al ., analysed large-scale metagenomic data and explored the potential function and distribution of unknown protein families, which might have evolutionary and ecological importance. Rodríguez del Río analysed nearly 150,000 microbial genomes (Fig. 1), and Pavlopoulos and colleagues investigated nearly 27,000 metagenomic data sets retrieved from diverse ecosystems with various bioinformatics approaches — going well beyond the scale of public-database entries used in previous such studies 8 . Surprisingly, a method called rarefaction analysis used by Pavlopoulos and colleagues revealed no slowing down in the detection of previously unknown protein families as new metagenomes were added to their analysis. Instead, the detection of protein families increased exponentially, warranting an array of follow-on studies.
The distribution of protein families across Earth’s categories of ecosystem (biomes) presented by Pavlopoulos and colleagues corroborates the findings of previous investigations regarding the distribution of microbial genes 8 . Some biological entities, however, were particularly rich sources of newly discovered protein families, including viruses, as Pavlopoulos et al . report, and microbes called Asgardarchaeota, as presented by Rodríguez del Río and colleagues. The latter are a group of microorganisms called archaea that are closely related to the first ancestor of eukaryotes. As such, studying their proteins might reveal new insights into the evolution of the eukaryotic cell 9 .
Crowdsourcing Earth’s microbes
One major challenge in exploring the wealth of previously unknown protein families encoded in genomes of natural samples is the identification of eukaryotic genes in metagenomes. Although certain algorithms exist for the recovery of eukaryotic genomes from metagenomes, accurately predicting eukaryotic genes in mixed DNA sequences — equivalent to Pavlopoulos and colleagues’ method of identifying microbial genes — is still not possible bioinformatically. Once this shortcoming is overcome with the development of new algorithms, scientists will substantially expand the protein ‘sequence space’ and will identify protein families of unknown function that drive the ecology and evolution of eukaryotes.
The greatest advance in painstakingly organizing the protein families of nearly 27,000 metagenomes and across the tree of life lies in the identification of ecosystem-specific protein clusters that differ in terms of their presence or absence, or relative abundance between varying conditions of a given ecosystem — for example, between the contexts of health or disease. Applying this strategy to examine microbial data for healthy people and those with colorectal cancer, Rodríguez del Río and colleagues found that specific unknown protein families were enriched in the gut bacteria of people with cancer. These protein families were associated with microbial motility, adhesion and invasion potentially of human tissue, as revealed through genomic-context analysis. Harnessing this approach in other fields of research should be extremely helpful for deciphering the different functions of sample sets, in the hope of identifying new targets for biochemical analyses to shed light on a tiny fraction of the microbial dark matter.
Identifying differences in microbial communities (microbiomes) that might explain, for example, the disease state of a person, rely heavily on comparing which species are present and how abundant they are (the taxonomic composition), and examining genes that are associated with certain functions. Finding specific but differentially abundant protein families of unknown function, as demonstrated by Rodríguez del Río and co-workers, has the potential not only to replace current marker-gene-based approaches for differentiating microbiomes but also to advance microbiome research to a new and causality-driven level.
Nature 626 , 267-269 (2024)
doi: https://doi.org/10.1038/d41586-024-00077-w
Rodríguez del Río, A. et al. Nature 626 , 377–384 (2023).
Article Google Scholar
Vanni, C. et al. eLife 11 , e67667 (2022).
Article PubMed Google Scholar
Pavlopoulos, G. A. et al. Nature 622 , 594–602 (2023).
Jumper, J. et al. Nature 596 , 583–589 (2021).
Doron, S. et al. Science 359 , eaar4120 (2018).
Illergård, K., Ardell, D. H. & Elofsson, A. Proteins 77 , 499–508 (2009).
Tyson, G. W. et al. Nature 428 , 37–43 (2004).
Coelho, L. P. et al. Nature 601 , 252–256 (2022).
Eme, L. et al. Nature 618 , 992–999 (2023).
Download references
Reprints and permissions
Competing Interests
The authors declare no competing interests.
Related Articles

See all News & Views
- Microbiology

Bird flu in US cows: is the milk supply safe?
News Explainer 25 APR 24

WHO redefines airborne transmission: what does that mean for future pandemics?
News 24 APR 24

Monkeypox virus: dangerous strain gains ability to spread through sex, new data suggest
News 23 APR 24

Exploring the lung microbiome’s role in disease
Outlook 17 APR 24

Gut bacteria break down cholesterol — hinting at probiotic treatments
News 02 APR 24

A host–microbiota interactome reveals extensive transkingdom connectivity
Article 20 MAR 24

Ecologists: don’t lose touch with the joy of fieldwork
World View 24 APR 24

Emx2 underlies the development and evolution of marsupial gliding membranes
Article 24 APR 24

Ancient DNA traces family lines and political shifts in the Avar empire
News & Views 24 APR 24
Postdoctoral Fellowships: Early Diagnosis and Precision Oncology of Gastrointestinal Cancers
We currently have multiple postdoctoral fellowship positions within the multidisciplinary research team headed by Dr. Ajay Goel, professor and foun...
Monrovia, California
Beckman Research Institute, City of Hope, Goel Lab
Postdoctoral Associate- Computational Spatial Biology
Houston, Texas (US)
Baylor College of Medicine (BCM)
Staff Scientist - Genetics and Genomics
Technician - senior technician in cell and molecular biology.
APPLICATION CLOSING DATE: 24.05.2024 Human Technopole (HT) is a distinguished life science research institute founded and supported by the Italian ...
Human Technopole
Postdoctoral Fellow
The Dubal Laboratory of Neuroscience and Aging at the University of California, San Francisco (UCSF) seeks postdoctoral fellows to investigate the ...
San Francisco, California
University of California, San Francsico
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Malays J Med Sci
- v.30(6); 2023 Dec
- PMC10793127
DNA Profiling in Human Identification: From Past to Present
Sundararajulu panneerchelvam.
1 School of Health Sciences, Universiti Sains Malaysia, Kelantan, Malaysia
Mohd Nor Norazmi
2 Malaysia Genome and Vaccine Institute, National Institutes of Biotechnology Malaysia, Selangor, Malaysia
Forensic DNA typing has been widely accepted in the courts all over the world. This is because DNA profiling is a very powerful tool to identify individuals on the basis of their unique genetic makeup. DNA evidence is capable of not only identifying the presence of specific biospecimens in a crime scene, but it is also used to exonerate suspects who are innocent of a crime. Technological advancements in DNA profiling, including the development of validated kits and statistical methods have made this tool to be more precise in forensic investigations. Therefore, validated combined DNA index system (CODIS) short tandem repeats (STRs) kits which require very small amount of DNA, coupled with real-time polymerase chain reaction (PCR) and the statistical strengths are used routinely to identify human remains, establish paternity or to match suspected crime scene biospecimens. The road to modern DNA profiling has been long, and it has taken scientists decades of work and fine tuning to develop highly accurate testing and analyses that are used today. This review will discuss the various DNA polymorphisms and their utility in human identity testing.
Introduction
The role of forensic scientists is to analyse physical/biological trace evidence from a crime scene, victim or suspect using available tools and technologies, to enable reconstruction of a situation of interest. For decades, blood group and protein markers have been used in the identification and individualisation of human biospecimens ( 1 , 2 ). However, the nature of blood and protein markers is unduly compromised by the environment. In most cases, they are helpful to exclude rather than to include the alleged suspects. The advent of DNA fingerprinting and its application in 1986 ushered in a new approach in processing biological trace evidences such as blood, semen, tissue, teeth and bones ( 3 – 5 ). The time line shown in Figure 1 charts the efforts of various discoveries ultimately culminating in the sophistication of the current DNA profiling techniques used routinely. A reliable (standardised and consistent) method of human identification in criminal investigation is essential to ensure justice is upheld. Coupled with robust statistical analyses and database, the ability to distinguish one person from another with great certainty provide high confidence in establishing individualisation. DNA database can also help determine previous record of the suspect’s involvement with previous crimes; and to verify or negate the involvement of individuals charged with the crime. It should be noted that DNA profiling is not a standalone tool and should be analysed together with other important information obtained during the occurrence of a crime.

Development in DNA techniques that facilitated the development of DNA profiling. Since the discovery of the structure of DNA, various developments in techniques to characterise DNA have facilitated the discovery of DNA profiling methods
DNA Structure
DNA, the repository of all genetic traits of a human, is present in all nucleated cells except red blood cells in the form of a double helix structure tightly bound with histone proteins in chromosomes. DNA is unchangeable from cell to cell within an individual and contains all the genetic information necessary ( 6 , 7 ). In humans, there are 23 pairs of chromosomes—22 pairs of autosomal chromosomes and a pair of sex chromosomes—XX in females and XY in males ( 8 ). The DNA double helix consists of two polynucleotide chains comprising nucleotide monomers. Each nucleotide consists of a sugar (deoxyribose), a phosphate group, and a nitrogen-containing base, namely, adenine (A) thymine (T) guanine (G) or cytosine (C). Adenine always bonds with its complementary base, thymine, whereas cytosine always bonds with its complementary base, guanine. Hydrogen bonds between complementary bases hold together the two polynucleotide chains of DNA. A and G have a two-ring structure. C and T have just one ring. The distance between the two chains is kept constant by the base pairs (bp). This maintains the uniform shape of the DNA double helix. These bp (A-T or G-C) stick into the middle of the double helix, forming the rungs of the double helical spiral ladder ( 9 ).
DNA replication is the process in which DNA is copied. It occurs during the synthesis (S) phase of the eukaryotic cell cycle. DNA replication is a semi-conservative process initiated at specific point known as origin. It is a bidirectional process in which each strand of the double helix acts as a template. Strand separation is accomplished by helicase enzyme and the building of new complementary strand with complementary bases is accomplished by DNA polymerase with high fidelity ( 6 , 9 ). The two daughter molecules that are produced contain one strand from the parent molecule and one new strand that is complementary to it. As a result, the two daughter strands are both identical to the parent strands. DNA replication is thus a semi-conservative process since half of the parent DNA molecule is conserved in each of the replication cycle. Importantly, the DNA sequence is copied essentially unchanged into all daughter cells, providing an ‘exact match’ in the DNA profile obtained from various biospecimens of the same individual.
In density gradient centrifugation, DNA in solution exhibits two bands—one is denoted as the major band and a minor satellite band. There are 3 billion bp found distributed along the length of the 23 pairs of human chromosomes coding for approximately 30,000 genes ( 10 ). Segments of DNA that code for a specific protein are known as gene. These genes occupy only 1%–2% of the 3 billion bp and these gene specific sequences are known as coding regions. The remaining 98%–99% of human genome is made up of non-coding DNA ( 6 , 7 ). An allele is a modified or alternative form of a gene that is located on a specified position on a specific chromosome. Coding sequences are frequently interspersed with non-coding repeat sequences. Noncoding regions generally contain DNA sequences that may be either of a single copy or exist as multiple copies called repetitive DNA. Besides nuclear genome there are multiple copies of mitochondrial genome present in each of the human cell which are also used in forensic human identification ( 6 ).
DNA Polymorphism
Polymorphism in genetics means a trait that differs among individuals ( 6 , 11 ) and the term variation is frequently interchangeably used to denote a polymorphic trait. Prior to the introduction of DNA typing, blood groups, serum and salivary protein variation among individuals were used for identification/individualisation of human biospecimens. Variation in proteins is the manifestation of the variation in DNA. Variation in DNA sequence among individuals is termed as DNA polymorphism and is heritable. Variation in DNA sequence is due to mutation, which may arise due to replication error or induced by external agents such as radiation or chemical mutagens. Such new mutations in coding and noncoding sequences accumulate over a period of time and in consequence, no two humans share the same genome except identical twins who will share identical DNA. Hence DNA polymorphism is a DNA sequence variation that is not associated with any observable phenotypic variation and can exist anywhere in the genome, not necessarily in a gene. Hence DNA polymorphism means one of two or more alternative forms (alleles) of a chromosomal region that either has a different nucleotide sequence or it has variable numbers of tandemly repeated nucleotides ( 6 , 11 ). DNA polymorphism in human genome include single nucleotide polymorphisms (SNPs), variable number of tandem repeats (VNTRs), transposable elements (e.g. Alu repeats), structural alterations and copy number variations ( 6 ).
DNA Polymorphic Genetic Markers in Human Identification
Single nucleotide polymorphisms.
SNP is a single bp change, a point mutation, and the site is referred to as SNP locus. SNPs are base substitutions, insertions or deletions occurring at single positions in the genome of any organism. SNPs are the most common type of DNA variation, occurring with a frequency of one in 350 bp and accounting for more than 90% of DNA sequence variation ( 11 ). Most SNPs are found to be present in the non-coding regions of the genome. Due to their abundance, SNPs have become important genetic markers for mapping human diseases, population genetics and evolutionary studies ( 12 ). SNPs have become very important since technologies for DNA sequencing have become feasible and widely available ( 13 , 14 ). Lack of recombination make mitochondria and Y chromosome SNPs suitable as lineage markers and kinship testing in missing-persons cases ( 12 ).
Restriction fragment length polymorphisms
Bacteria are endowed with special molecular scissors known as endonucleases capable of cutting foreign DNA having specific recognition sites for that endonuclease. Restriction enzymes are site-specific DNAses that cleave a DNA molecule whenever the specific sequence is recognised, which is usually a 4–6 base palindrome. Each bacterium has its own unique restriction enzyme. Each endonuclease recognises only one type of sequence in the foreign DNA. Restriction enzyme recognition sites may be present in some genomes and absent in others. A specific endonuclease used to cut DNA of an organism having restriction sites for that enzyme will result in fragments differing in their length due to the different location of recognition sites along the length of the DNA of the organism ( 15 , 16 ). Two individuals belonging to the same species will differ in the number of restricted fragments and exhibit uniqueness. Due to the enzyme’s sequence specificity, digestion of a particular DNA results in a reproducible array of restriction fragment length polymorphisms (RFLPs) or length differences in homologous fragments between different DNA samples. These length differences can be the result of a point mutation obliterating an existing restriction site or generating new restriction site. Insertion or deletion of DNA between two restriction enzyme cut sites also result in new RFLP.
RFLP was one of the earlier profiling methods used for individualisation. However, the technique requires large amounts of DNA and is rather cumbersome to perform.
Tandem repeats
Satellite DNA is mainly present in heterochromatin or the tightly packed regions of chromosomes in centromeres, telomeres and sometimes even in the euchromatin region (active region of the genome). Satellite DNA consists of arrays of tandem repeats or repeats arranged side-by-side in a head-to-tail fashion. These repeats can be as small as 1 bp−6 bp long or it may be 9 bp−100 bp long. The short tandem repeats (STRs) (1 bp–6 bp long) are known as microsatellite or simple sequence repeats (SSRs), while the longer tandem repeats (9 bp–100 bp) are called minisatellites or variable number tandem repeats (VNTRs) ( 17 – 20 ).
The regions in between two simple sequence repeats or microsatellite are termed as ‘inter simple sequence repeats’ or ISSRs. Based on the length of the repeat motif, STRs are classified into mono-, di-, tri-, tetra-, penta- and hexanucleotide repeats. Dinucleotide repeats are the most abundant in the human genome. The short sequence of DNA stretches in satellite DNA varies from individual to individual. In forensic case work, tetra and penta nucleotide repeats are chosen and validated for use. STRs have higher mutation rate than SNPs. The mutation rate for SNPs is approximately 10 −9 per generation and for STRs it is 10 −6 to 10 −2 per generation. Three possible mechanisms for the high STR mutation rate have been suggested. They are (i) unequal crossing over in meiosis, (ii) retro-transposition mechanism and (iii) strand slippage replication. It is suggested that STR mutation rate increases proportionally with repeat number ( 21 , 22 ).
Unequal crossing over between homologous pairs of chromosomes in satellite DNA in meiotic prophase results in addition or reduction in the number of repeat units ( Figure 2A ). Sister chromatid exchanges in meiotic prophase also leads to increase or decrease of repeat units ( Figure 2B ).

Unequal cross over during meiosis
Retrotransposition mechanism suggest that STRs are generated by retrotranscripts. Further studies are required to elucidate the process.
Strand-slippage replication is also known as DNA slippage or slipped strand mispairing or DNA polymerase slippage. Most studies favour slippage as the main cause for STR mutation process. The mispairing in the region of repeat units between template DNA and the newly synthesised DNA occurs during DNA replication ( Figure 3 ) resulting in addition or reduction of STR number.

Strand-slippage replication resulting in addition or reduction in STR number. Also known as DNA slippage or slipped strand mispairing or DNA polymerase slippage. Most studies favour slippage as the main cause for STR mutation process. The mispairing in the region of repeat units between template DNA and the newly synthesised DNA may occur during DNA replication resulting in the addition or reduction of STR number
In 1993, the Commission of the International Society of Forensic Haemogenetics (ISFH) proposed the nomenclature method of STRs.
D7S820 is one of the common STRs used in DNA profiling. The D stands for DNA and the number following D indicates the chromosome on which the STR is located. S is for the STR sequence and 820 (in D7S820) is the unique sequence number ( 23 ). The STR alleles are named according to the number of repeat units it contains. The STRs are inherited in a simple Mendelian fashion. An individual inherits an allele each from his/her father and mother. A person may be homozygous (the same allele on the maternal and the paternal chromosomes) or heterozygous (different alleles on the two chromosomes). STRs used in forensic human identification are from autosomal (autosomal STRs), Y (Y STRs) and X (X STRs) chromosomes ( 24 – 30 ). Autosomal STRs used in DNA profiling are single locus multiple allelic markers used for identification and individualisation of forensic biospecimens and for ascertaining parentage in paternity cases.
The X and Y chromosomes are inherited in unique ways depending on the sex. The X chromosome consists of hundreds of genes. The Y chromosome contains sex determining region (SRY) gene and most of the Y chromosome is made of noncoding DNA. In males, the X and Y recombine at the pseudo autosomal region (PAR region), hence, the greater part of X and Y chromosome is inherited without recombination in meiosis ( 31 , 32 ). The X chromosome is in pairs in females, and they undergo extensive recombination and inherited. The X or Y chromosome from a male is inherited to his daughter or son, respectively, without recombination. While the X chromosome from females are inherited to both sexes with recombination. The lack of recombination makes Y STRs to be inherited as a haplotype and all male descendants from a male lineage share the same STRs. The Y STRs are more frequently used in rape cases. Y STRs are more useful in gang rape cases to identify male individuals from the mixed biospecimen from females.
A robust database is available for the distribution of Y STRs haplotypes and for Y SNPs for various populations and provides forensic investigators with clues to the source of the male genetic material left at a crime scene (YHRD) ( 33 ). Haplotype frequency data for X chromosome STRs is available in ChrX-STR. org 2.0 ( 34 ). This database covers many issues concerning the usage of X-chromosomal markers for forensic purpose. X STRs are more useful as supplementary data for discrimination of individuals in incest cases.
Mitochondrial DNA
Mitochondria are cytoplasmic organelles present in multiple copies ranging from 500–1,000 in human cells. Each mitochondrion contains extra chromosomal circular DNA devoid of bound histone proteins ( 35 , 36 ). The complete sequence of human mitochondrial DNA (mtDNA) genome was ascertained and it is known as the Cambridge Reference Sequence (CRS). The mtDNA of humans is about 16,569 bp ( 37 , 38 ). The two strands of the circular mtDNA differ in densities due to base composition and they are referred as heavy and light chains. The heavy chain contains more genes compared to the light chain. The mtDNA genes of humans are devoid of introns. The origin of replication is present in the control region which is about 1.2 kb in length, which is the noncoding part of the mtDNA consisting of highly polymorphic hypervariable (HV) regions. This stretch of noncoding sequence consists of the hypervariable HVI, HVII and HVIII regions ( 39 ). The mtDNA does not have DNA repair mechanisms and as a consequence has high mutation rate compared to nuclear genome. mtDNA is passed from one generation to the next, essentially unchanged, solely through the maternal line of a family. During fertilisation of an egg the male sperm does not typically contribute mitochondria to the offspring. Hence there is only one mtDNA genotype (that of the mother) in an individual and all mitochondrial genomes are approximately genetically identical, and the condition is known as homoplasmy. In many mitochondrial diseases, however, since the number of copies of mitochondria within a particular cell is high, wild-type and mutant maternal alleles coexist, and this is known as heteroplasmy ( 40 , 41 ).
DNA Profiling Techniques
DNA profiling is also known as DNA typing, DNA fingerprinting, genetic fingerprinting, genotyping or identity testing. However, the term DNA profiling is more preferred since a wide range of tests are carried out by DNA sequencing with improved technology. The DNA profiling technique has evolved in three phases. First was the use of multi-locus VNTR probe-based RFLP developed by Sir Alec Jeffreys ( 42 ). The second phase utilised single locus probe (SLP)-based RFLP. Finally, the third phase, which is the present DNA profiling technique uses STR. All DNA profiling methods involve four basic strategies that include extraction of DNA from the source biospecimen, quantification, electrophoresis and detection.
RFLP Using MLP/SLP Probes (Phase 1 and 2)
The original DNA profiling developed by Sir Alec Jeffreys involved the use of a multi-locus probe (MLP) against the VNTR across the human chromosomes ( 3 , 4 , 42 ). High molecular weight DNA extracted was subjected to restriction enzyme digestion. The restricted DNA was then separated in agarose gels using electrophoresis in the presence of a radioactive labelled DNA marker. Electrophoresis separates the restricted fragments towards the positive end depending on their size. Smaller fragments which move faster will be at the bottom of the gel and the longer fragments which move slower are closer towards the negative end. Double stranded DNA fragments in the gel were then converted to single strands by denaturation before being transferred to a nylon membrane for autoradiography ( 43 ). Radioactive labelled MLP was then used to hybridise to the single stranded DNA fragments on the nylon membrane. Then the nylon membrane was exposed to an X-ray film. The various steps in RFLP technique is shown in Figure 4 . Dark bands appear on the X-ray film due to the binding of radioactive labelled probe with the complementary VNTR carrying fragments. The band patterns obtained are unique to an individual where discrete bands of between 6 and 8 bases are enough to distinguish between different individuals. The first application of DNA profiling in forensic identification was in 1985 in a case that exemplifies the power of DNA evidence to link crime-scenes, to exclude suspects and to support convictions.

Identification of VNTR using a labelled MLP
In that particular case, a suspect was arrested for allegedly raping and murdering two minor girls in a UK suburb. The suspect was arrested based on suspicion. DNA profiling using MLP on a sample of semen left in the crime scene demonstrated that a man had been responsible for both crimes. But the profile did not match with the arrested person who was subsequently released. Police decided to flush out the killer by taking blood samples from adult males residing in the surrounding villages. After testing 4,852 male samples, the 4853rd sample tested matched the semen DNA profile. The suspect was arrested and subsequently sentenced ( 3 ).
The technique was met with almost universal acceptance and admissibility in court. Defence attorneys struggled unsuccessfully to demonstrate the potential flaws and setbacks of the early technology. During the first string of cases, law enforcement agencies sent evidence samples to private biotechnology companies for analysis. At the same time, defence attorneys struggled to combat DNA-based evidence in court because the technology used by the private companies was strongly backed by scientific methods.
Meanwhile the US Federal Bureau of Investigation (FBI) assumed a role of standardising the technique of DNA fingerprinting in forensic DNA analysis and attempted to standardise most of the methods and procedures. Controversies led to new concerns regarding laboratory error and regulation ( 44 , 45 ).
Further, DNA analyses with RFLP required comparatively large amount of high molecular weight DNA. Degraded samples could not be examined with precision. A single band is sometimes ambiguous, because it may be from a homozygote or from a heterozygote. The small differences between adjacent alleles necessitated grouping them into ‘bins’, which complicated the statistical analyses. As an alternative to MLP/RFLP, many single locus VNTRs ( 17 ) were recognised and single locus probes (SLPs) were constructed so the DNA strands only bind with the alleles at one specific locus. The band patterns produced by SLP technology are easier to read and the results also allowed for more precise frequency statistics because data can be collected regarding how often different alleles occur at these specific locations among different populations. To produce significantly individualised results, multiple SLP tests have to be performed. Six genetic loci namely D1S7, D2S44, D4S139, D10S28, D14S13 and D17S79 were recommended for use. However, VNTR testing was still problematic. The technique was not very efficient, gel electrophoresis measurements were messy and far from exact, and large amount of DNA samples were needed ( 45 ). Forensic DNA samples frequently are degraded or are collected post-mortem, which means that they are of lower quality and prone to provide less-reliable results than samples that are obtained from a living individual. Some of the concerns with DNA profiling, and specifically the use of RFLP, subsided with the development of polymerase chain reaction (PCR) and STRbased profiling which, is now the primary technique used, to replace the RFLP-based on MLP/SLP method of DNA profiling.
Polymerase Chain Reaction
The next advancement of DNA typing technology started with the discovery of PCR ( 46 ). This revolutionary technology enabled scientists to amplify a specific segment of DNA in a machine designed to carry out many cycles of replication providing a large quantity required for analysis. PCR is an in vitro exponential amplification of a specific segment of DNA from a small amount of DNA, typically less than 1 mg ( 47 ). There are four important components in the PCR process: i) the DNA template, ii) oligonucleotide primers, iii) DNA polymerase and iv) deoxynucleotide triphosphates (dNTPs). The DNA template consists of the target DNA sequence to be amplified whilst the oligonucleotide primers are short single stranded DNA molecules that bind with complementary base pairing to opposite strands of the template DNA at either end of the sequence to be amplified ( 46 , 47 ). The DNA polymerase is an enzyme that copies the target sequence ( 33 ). Taq polymerase is the commonly used DNA polymerase as it is thermostable at high temperatures, which can effectively copy the original template DNA by extending the primers and making complementary copies of the original template DNA. dNTPs refer to the four bases present in DNA (A, G, T and C) which are used by the DNA polymerase as building blocks to synthesise new DNA strands. The target DNA is amplified over several cycles. Each cycle has three stages carried out at different temperatures—consisting of denaturation, annealing and extension of the target DNA in a single cycle.
STRs Typing Technique
Autosomal str analysis.
Presently, PCR-based autosomal STRs, is the technique used routinely in forensic labs for identity and individualisation. The autosomal STRs chosen for DNA profiling comprises tetra and penta core repeat STRs with no linkage located on different sets of chromosomes ( 48 , 49 ). The primer sets for amplification of various STRs are designed to facilitate multiplexing of primers, which means that several primer sets can be used to amplify multiple target STRs at the same time. The PCR STR method essentially involves amplification of STRs using primers in a PCR machine and separation of the fragments corresponding to allelic ladders and detection of the fragments ( 50 , 51 ). The first commercial kits were triplex STR kits using polyacrylamide gel electrophoresis (PAGE) for separation of fragments carrying STRs alleles, which were then detected with silver stain or fluorescence.
In 1998, the FBI developed the combined DNA index system (CODIS) data for 13 STRs which are stored data of DNA profiles obtained from convicted persons and unidentified DNA profiles from crime scene biospecimens. These STRs are known as CODIS STRs ( 50 ). Later, commercial kit multiplexing primers for 15 STRs and amelogenin gene for sex determination, were made available which further enhanced the CODIS STR database ( 52 ). STR primers are labelled with different fluorophores. The kits contain allelic ladder and internal size ladder. The amplified unknown DNA samples with these kits were electrophoresed in capillaries in an automated fragment analyser/gene sequencing machine. Capillary electrophoresis (CE) is an electrophoretic separation within a small diameter capillary, a long tube made of fused silica, typically 50 μ internal diameter that is filled with a sieving medium. The sieving medium is typically an entangled polymer that is designed to separate DNA fragments based on size. The multiplex/multicolour PCR products for each sample are combined with an internal size standard (DNA fragments of known size labelled with a different dye colour), heat denatured, then placed in a 96-well tray on the CE instrument. Electrophoresis through the sieving medium in the capillary separates the DNA fragments by size. A laser continuously illuminates a detection window that is located near the end of the capillary. The fluorescently tagged DNA molecules are detected during electrophoresis as they reach this laser detection window. Smaller DNA molecules reach the window before larger molecules ( 50 – 53 ). The software in the genetic analyser translates fluorescence intensity data into electropherograms and then labels any detected peaks with such descriptors as size in nucleotides and peak height in relative fluorescence units or RFU. Using allelic ladders as reference, the software then labels peaks that meet certain criteria with allelic designations and the resulting electropherogram contains genotype of the individual/biospecimen for the tested STRs. The steps involved in STRs-based DNA profiling are shown in Figure 5 . The kits are so sensitive and require only about 1 ng of DNA sample for amplification. To date, although most laboratories use the 15 STRs kits, assays that measure 23 or more STRs are now available, increasing the discrimination probability of STR DNA profiling. Autosomal STR-based DNA profiling is now routinely used in processing biospecimens from crime scene and in parentage testing.

General principle of the STR technique for DNA profiling. Unknown DNA samples are extracted and quantified before being amplified by PCR using specific STR primers labelled with different fluorophores. The amplified DNA samples are then electrophoresed in capillaries containing polymer to separate the labelled DNA according to size in an automated fragment analyser/gene sequencing machine. The fluorescently tagged DNA molecules are detected and the software in the genetic analyser translates fluorescence intensity data into electropherograms against a set of allelic ladders as reference. The software then labels peaks that meet certain criteria with allelic designations and the resulting electropherogram contains genotype of the individual/biospecimen for the tested STRs
Sex-chromosome STRs
Commercial kits are also available for amplification of Y and X STRs. The method of analysis is the same as that of autosomal STRs. The Y STRs and X STRs are routinely used in gang rape and incest cases to provide supportive evidence and for greater discrimination in addition to autosomal STRs ( 54 – 56 ).
Population database and interpretation of STRs profiling data
The STR profile obtained from a crime scene sample may provide three interpretations when compared to that of a suspect: i) Exclusion: the sample profile did not match with the suspect’s profile; ii) Inclusion: the STR profile from the crime scene specimen matches with that of the suspect’s STR profile and iii) Inconclusive: no decision possible. The DNA typing data from a crime scene provides the genotype comprising two alleles for each of the STRs tested—one from the maternal chromosome and the other from the paternal chromosome.
Exclusion does not require any statistics but inclusion requires statistics to provide verbal predicate of how reliable the match is. Random match probability (RMP) is the statistical approach used to assess that the DNA profile is unique and that it is unreasonable that another person in the population might have the same STR profile. The RMP is calculated applying product rule of genotype frequencies of alleles in the population to which the suspect belongs. Hence RMP is dependent on the distribution of allele frequencies in a population which is in Hardy-Weinberg equilibrium (HWE). HWE is the foundation for population genetics and explains how populations continue unchanged in allele frequencies (and thus phenotype) unless acted on by one of the four evolutionary forces namely mutation, selection, gene flow (or admixture) and drift. Usually, a sample size of greater than 100 samples is sufficient to make reliable projections about a genotype’s frequency in the larger population ( 57 , 58 ). Published STR allele frequency distribution of various populations is available in STR base ( 59 ).
It would be appropriate to explain the calculation of RMP with an illustration. Consider a case in which the bloodstain from a crime scene was DNA profiled for three STRs. Two individuals were arrested on suspicion in that case. Biospecimens from the two were tested for the same three STRs. The hypothetical case data is provided in Table 1 .
Calculation of RMP in a hypothetical case
The expected genotype frequencies of a population in HW for two alleles p and q are equal to the proportion: p 2 + 2pq + q 2 . Applying this rule, the frequencies of the alleles are calculated and the RMP is calculated following the product rule that is, multiplying the genotype frequencies as shown in Table 1 .
The RMP tells how likely it is that a random person’s DNA profile will match the crime sample. To take the match probability into account one has to calculate the likelihood ratio (LR).
The LR measures the impact of the evidence. For the case in Table 1 , suspect 2 was guilty then his DNA profile would match the crime sample, and so the probability of observing this evidence is 1. If suspect 2 was not the culprit, then the probability of observing the evidence (the denominator in the LR) is just the random match probability. So, the LR is simply the reciprocal of RMP. The LR measures the impact of the evidence.
In paternity, testing LR is also known as paternity index (PI) which is the ratio of the chance that the alleged father (AF) would transmit the obligate allele to that of the chance that some other man of the same race could have transmitted the allele (population frequency). The PI for each genotype is calculated by multiplying individual PIs to obtain the combined PI (CPI). The CPI is a measure of the strength of the genetic evidence. It indicates whether the evidence fits better with the hypothesis that the tested man is the father or with the hypothesis that someone else is the father. Then the genetic evidence is converted to probability of paternity (POP) using Bayesian theorem. The CPI is used in the Bayes formula along with another variable called a prior probability (PP). This variable represents the social evidence. Testing labs typically use a value of 0.5 for the PP assuming this is a neutral, unbiased value. The Bayesian formula is CPI / CPI + (1 − PP) × 100. The statistics for paternity calculation is illustrated with a hypothetical paternity test case for three STRs in Table 2 .
Calculation of probability of paternity in a hypothetical case
- Alleged father (AF) = X = 1 if homozygous; 0.5 if heterozygous;
- Random man = Y = allele frequency
Low copy number DNA typing
The potential of STR-based DNA typing is widely accepted in various courts. Tabereit et al. ( 60 ) published genotyping of samples with very low DNA quantities using PCR. The sensitivity of routine STR typing requires 0.5 ng–2 ng of DNA template and 1 ng being the recommended quantity in many kits. The sensitivity of STR typing using second generation multiplex (SGM) kits is as low as 100 pg. The low copy number (LCN)-based STR typing involves mainly increasing the number of PCR cycles from normal 28 to 34 and above. LCN method is used to analyse DNA from charred human remains and minute amounts of blood. LCN typing has greater potential for errors in amplification. It is also suggested that the LCN results are not reproducible, which undermines the probative value of the results. LCN is mainly used in analysing ancient samples from decomposed bones by anthropologists and forensic scientists. The LCN typing is also known as trace DNA typing and touch DNA typing ( 60 – 64 ).
Combined DNA index system
CODIS blends computer and DNA technologies into an effective tool for fighting violent crimes. The current version of CODIS uses two indices to generate investigative leads in crimes where biological evidence is recovered from the crime scene. The convicted offender index contains DNA profiles of individuals convicted of theft, sex offences and other violent crimes. The Forensic index contains DNA profiles developed from crime scene evidence. CODIS utilise computer software to automatically search these indexes for matching DNA profiles. CODIS does not store criminal history information, case-related information, social security numbers or date of birth. DNA examiners use CODIS software and transfer unknown subject profiles into forensic index, where they are searched against other unknown subject profiles. Forensic profile developed at local laboratories is also searched against the convicted offender index. A match known as ‘cold hit’ provides the police with an investigative lead. To begin with, the FBI included 13 STRs as core CODIS STRs so all the data compiled in the two indexes had the genotype for the 13 STRs. In 2017, the FBI increased the core STRs from 13 to 20 ( 65 ) comprising: CSF1PO, FGA, THO1, TPOX, VWA, D3S1358, D5S818, D7S820, D8S1179, D13S317, D16S539, D18S51, D21S11, D1S1656, D2S441, D2S1338, D10S1248, D12S391, D19S433, D22S1045 and amelogenin. Many countries have since emulated the FBI and compiled CODIS concept and database.
Mitochondrial DNA Typing
The mtDNA sequence typing used in forensics primarily involves sequencing of the hypervariable (HV) regions, HV1 (positions 16,024–16,365), HV2 (positions 73–340) and HV3 (positions 438–574) ( 66 – 71 ). Direct sequencing is normally performed using the ABI 310/3130/3730/3730xl or next generation sequencer (NGS). Sequencing is done on these instruments using the Sanger’s dideoxy chain termination method. The incorporation of dideoxy nucleotides in newly synthesised DNA strands results in termination of the elongation process ( 13 ). The small size and relatively high inter-person variability of the HV regions are very useful features for forensic testing purposes.
A person is considered as heteroplasmic ( Figures 6A and 6B ) if she/he carries more than one detectable mtDNA type. There are two classes of heteroplasmy, related to length polymorphisms and to point substitutions ( 72 , 73 ). Only the latter is important for forensic human identification. Heteroplasmy manifests itself in diverse ways. An individual may show more than one mtDNA type in a single tissue. An individual may be heteroplasmic in one tissue sample and homoplasmic in another one. Furthermore, an individual may exhibit one mtDNA type in one tissue and a different type in another tissue. Of the three possible scenarios, the last one is the least likely to occur. The mtDNA sequence of siblings and all maternal relatives is identical provided there is no mutation. The shared identical mtDNA in all maternal relatives is known as homoplasmic. However occasional heteroplasmy may be observable in maternal relatives due to mutation.

Heteroplasmy in mtDNA. The maternal transmission of mtDNA results in homoplasmic individuals, who typically have a single mtDNA haplotype, the maternal one. Heteroplasmy is the presence of more than one type of mtDNA within an individual. A person is considered as heteroplasmic if she/he carries more than one detectable mtDNA type. Sequence chromatogram showing heteroplasmy in the HVS-I region, at the nucleotide position indicated A): G and A and B): T and C
Heteroplasmy played an important role in identifying the bones of Tsar Nicholas II among nine sets of bones excavated in a mass grave near Yekaterinburg, in 1991. mtDNA sequences from bone of the presumed Tsar matched two living maternal relatives except at a single position, where the bone sample had a mixture of matching (T) and mismatching (C) bases. Cloning experiments indicated that this mixture was due to heteroplasmy within the Tsar. At the request of the Russian Federation government, the skeletal remains of the Tsar’s brother Georgij Romanov was analysed in order to gain further insight into the occurrence and segregation of heteroplasmic mtDNA variants in the Tsar’s maternal lineage. The mtDNA sequence of Georgij Romanov matched that of the putative Tsar and was heteroplasmic at the same position. This confirmed heteroplasmy in the Tsar’s lineage and it was powerful evidence supporting the identification of Tsar Nicholas II ( 74 , 75 ).
In forensic analysis, both mtDNA sequences of a reference sample and an evidence sample(s) are compared. If the mtDNA sequences are identical, the samples cannot be excluded since they must have the same origin or derive from the same maternal lineage. Similarly, samples cannot be excluded when heteroplasmy is observed at the same nucleotide positions in both samples. Similarly, when one sample is heteroplasmic and the other is homoplasmic but they both share at least one mtDNA species, the samples cannot be excluded since they may have the same origin. It is suggested that samples with mtDNA with one-base difference should be further evaluated, mainly regarding their rate of mutation ( 39 ). When two or more nucleotide differences exist between the two sequences, the overall interpretation is exclusion.
mtDNA sequence from an evidence sample and one from a known reference sample cannot be excluded as originating from the same source, it is desirable to convey some information about the mtDNA profile’s rarity. The current practice is to count the number of times a particular sequence is observed in a population. The sequence of HV region from the haploid mtDNA genome is known as haplotype. Similar sequences form a group called haplogroup. Haplotype frequency is a measure of how commonly the sequence is present in a specific population and therefore, is a measure of discriminatory power. Mitochondrial haplotype database in EMPOP and Mitomapare sources for analysing the forensic data. mtDNA analysis is an appropriate method to use for charred remains, degraded specimens, old skeletal and fingernail samples, hair shafts etc. mtDNA is of value in identifying mass disaster victims and in cases where the DNA is degraded or the source of the sample does not contain enough genomic nuclear DNA for analysis ( 74 – 76 ).
Quality Assurance
DNA typing using STRs is widely accepted as infallible evidence in crime and kinship testing. To provide quality in the standard of analysis and interpretation, a group of scientists was formed by the FBI-Scientific Working Group on DNA Analysis Methods (SWGDAM) ( 77 ). This group prescribes certain standards regarding the procedure of carrying out DNA typing and provide guidelines on interpretation of electropherogram results in STR typing. It also prescribes qualification of analysts and their duties. It prescribes for internal and external audit of DNA lab and a prescription for proficiency testing of DNA analysts.
Autosomal STRs-based DNA profiling has proven as an incredible technique in identification and individualisation of human biospecimens collected from crime scenes. The technique and related statistics for interpretation are robust and highly reproducible. Methods of automation, increasing the speed and output and reliability of STR methods will continue, and continued research may pave way for portable, miniature chips to allow analysis of DNA directly at the crime scene.
Acknowledgements
Conflict of Interest: None.
Funds: None.
Authors’ Contributions: Conception and design: SP, NMN
Analysis and interpretation of the data: SP, NMN
Drafting of the article: SP, NMN
Critical revision of the article for important intellectual content: SP, NMN
Final approval of the article: SP, NMN
- Customer Stories
- Subscribe to Blog
- go to FamilyTreeDNA.com
Unraveling the Spiral: A Celebration of DNA Day
By: Jim Brewster
From the discovery of cells to the mapping of the human genome, let’s celebrate DNA Day by tracing the remarkable scientific progress that unlocked the secrets of genetics.
Ah, DNA Day. The day when we celebrate, well, DNA. At first glance, you may be rather underwhelmed by such a commonplace substance.
Why have a whole day devoted to spirals? You do that every time you eat rotini, right?
April 25 is the day in 1953 when a paper published by James Watson and Francis Crick definitively described the structure of DNA as a double helix chain. DNA Day celebrates this achievement, but to me, what it really celebrates is the monumental advances in science that brought us the understanding we have today of the fundamental building blocks of life.
The iconic double helix is ubiquitous in our society, but when you step back and think about how we as a species were able to discover the intricate beauty of something so tiny, it really boggles the mind.
The average human is made of 36 trillion cells. In each cell is a nucleus, and in each nucleus is DNA. The DNA weighs less than six picograms. How much is a picogram? I have no idea, but after a bit of Googling, I discovered that the mathematical formula for it is one divided by a lot. Not only is it tiny, but it is composed of even smaller bits of information that are vital to the proper function of life.
Determining the information inside a chromosome, inside a nucleus, inside a cell, and inside your body is known by many as genetics and by literally no one as in-cell-ption. I am hoping incellption catches on, though, since it is a way punnier name.
As a species, how did we dig out this information and determine the elegant double helix structure we all now recognize?
How did we go from realizing a cell exists to recognizing the entire human genome?
Come along, friends and neighbors, as we start at the top layer of the incellption and work our way down. This journey has it all: words, punctuation, and even the occasional picture!
Unveiling the microscopic world and the discovery of the cell
Today, this term is best known as the sole contents of an orange cat’s head, but the term comes from a very different source. In 1665, Robert Hooke refined the microscope with multiple lenses to produce a magnification of 200x. This allowed the study of “microscopic” organisms for the first time. After observing cork under his newfangled contraption, he saw structures that reminded him of the living quarters of monks (the original meaning of the word cell). Thus the name was coined in his succinctly titled, Micrographia: or Some Physiological Descriptions of Minute Bodies Made by Magnifying Glasses . With Observations and Inquiries Thereupon .

Shortly after the publication of Hooke’s, I Couldn’t Think of a Shorter Title, the Dutch scientist Antonie van Leeuwenhoek picked up a microscope and started examining bacteria and microbes for the first time. He saw these tiny “animals” wiggling around, living their best microscopic lives, and named them “animalcules.” It became clear that these animalcules were present in people, too, but what exactly were they? How did they reproduce? How did they feel about pineapple on pizza? These questions and more would remain unanswered for quite some time.
Unraveling the enigma of the nucleus
Since cells are teeny tiny animals, they have teeny tiny organs called organelles. The first of these to be discovered was the nucleus. Our buddy van Leeuwenhoek first described them in the red blood cells of salmon and named them “lumen.” It wouldn’t get the name we all know today until 1831 when a Scottish botanist, Robert Brown, called this opaque area (which was all the resolution of the day would show) the “nucleus.” The function of the nucleus, however, remained unclear for quite some time. A series of experiments in the mid-1800s demonstrated it played some role in heredity and that it was essential to cell formation, but the mystery of what it actually did would have to wait until the next layer of incellption that was uncovered in the late 1800s and the first years of the 20th century.

Painting a picture of inheritance through chromosomes
Advances in magnification and cell staining led to the discovery of structures within the nucleus. Cell staining is adding a dye to a culture to better identify the structures within. This lends the chromosome its name, as it combines the Greek words for color ( chroma ) and body ( soma ). This ability for chromosomes to absorb dye was later observed by Paul Simon, who described it in his 1973 classic hit “ Chromosome .”
“Chromosome Give us those nice bright colors Give us the greens of summer Make you think all the world is a celly day oh yeah”
At least I think that’s how the song went. The same method is widely used today and even used to add clarity to CT scan images. The ability to clearly discern the shape of chromosomes was important for recognizing them as the key factor in inheritance. By identifying the shapes and number of chromosomes, it definitively proved that chromosomes were inherited in equal numbers by both parents and, therefore, a key factor in heredity. This led to the final level of incellption, and the actual focus of this article: DNA.
DNA’s structural revelation
The seminal paper published by Watson and Crick in April 1953 that described the structure of DNA was actually a culmination of work done by several other scientists on the chemical properties and helix shape of DNA. This can be summarized in three sections: Nucleic acid, nucleotides, and helix shape.
Nucleic acid
In the late 1800s, a Swiss physician, Johannes Miesher, tested the contents of the newly discovered nucleus and found it to be an acidic mixture that was high in phosphorus and nitrogen. He called this mixture “nuclein,” which was later renamed “nucleic acid” due to its high acidity. Personally, I want to live in the alternate reality where animalcules are powered by nuclein, because that just sounds cooler, but oh well.
Later studies showed the nucleic acid to include polymer chains held together with sugar called deoxyribose. Thus the mixture was called deoxyribose nucleic acid, or, as we more commonly know it, DNA.
DNA was also found to contain four specific chemicals: adenine, guanine, thymine, and cytosine. These are rather big words (unlike all the other jargon in this article, right?), so we will just refer to them by their first letters: A, G, T, and C. Today, we know these as “nucleotides” and understand their significance, but for a long time their pattern wasn’t recognized. Nucleotides were thought to be just another part of the homogenous nucleic acid and thus incapable of containing the information needed for hereditary traits. It was written off as a curiosity and attention was turned to proteins as the building blocks for quite some time.
Nucleotides
In the 1940s, a rather clever biochemist named Erwin Chargaff began studying nucleic acid using a technique called chromatography. This is a way to separate the components of a mixture to measure their amounts.
Chargaff began to see that the amount of each of the four nucleotides were not random, or homogenous, but tended to be consistent within a species. It might vary from one species to another, but within a species it was always the same, and not only that, but the amount of T was always roughly equivalent to the amount of A, and the same was true for G and C.
For example, if a nucleus contained 20% T, It also had 20% A. The remaining 60% was split evenly between G and C. The significance of this was that the mixture was not homogenous as previously thought, and this brought attention back to DNA as the candidate for the information passed along in heredity.
Helix shape
At the same time Watson and Crick were investigating the structure of DNA, Rosiland Franklin and Maurice Wilkins were exploring the shape of chromosomes using X-rays. X-rays shoot through an object, bounce around, and reflect back. Things with different densities will bounce around at different rates, and with this we can tell the internal structure of an object. This is how the dentist is able to discover all the cavities in your mouth, because teeth have a different density than the lack of teeth.
Franklin and Wilkins used this method to discover the structure of the chromosome known to reside in the nucleus thanks to earlier chromatographic pictures and stains. In the same 1953 edition of Nature, where Watson and Crick published their study on the structure of DNA, Franklin and Wilkins each published papers on the internal structure of chromosomes using X-ray imaging. Together, these papers demonstrated that DNA was made of a helical (spiraling) polymer chain, with evenly spaced, two chain nucleotides attached to it horizontally. In other words, it was a spiral chain of phosphate “backbone” with nucleotide pairs running all along it.
However, the number of nucleotides on each “row” was surmised based on the width of the spiral and the number of molecules that could fit side by side inside such a spiral. They guessed that there must be more than one intertwined polymer chain, but the number of chains and the way they connected to the nucleotides was anyone’s guess.
Double helix structure
Enter James Watson and Francis Crick. Working at Cambridge University, these two scientists sat down with the different lines of evidence we had so far about DNA:
- Deoxyribose nucleic acid is the main component.
- The ribose is made up of spiraling chains of phosphate and nitrogen.
- Attached to the chain are pairs of the nucleotides A, C, T and G.
- The amounts of A and T are equal, and the amounts of G and C are equal.
So, what can we do with this information? The two made ball-and-stick models of the molecules involved and found that A and T just fit together, and G and C just fit together. Fitting means they don’t get in each other’s way, but nothing is holding them together, either. However, A doesn’t fit with G or C, and G and C don’t fit with T. If each row has two nucleotides, and A and T are in equal amounts, then it follows that each row is a fitted AT pair. The same logic holds true for GC pairs. Now we have the pairs identified on each row. So far, so good.
Next, how do they fit to the backbone? Earlier models suggested a central core of phosphate with the nucleotides sticking off the sides. All four can bind to the backbone well. Binding means they share a hydrogen atom and make the atoms inseparable. That meant that if A was attached to the backbone, it wasn’t going anywhere, but nothing was stopping T from falling right off A on the other side. Not a great setup if you want something that will survive generations without parts falling off all over the place.
Instead, they tried making a model with two phosphate chains (because, remember, Franklin and Wilkins said there were probably more than one) that had the nucleotide pairs sandwiched in between them. Voila! The space was just enough to hold the nucleotides in place, but they were not bound. If you unwound the two strands, each nucleotide would stay exactly where it was supposed to be, and when you wound it back together, it would be right next to its partner. In their paper, they even noted, “It has not escaped our notice that the specific pairing we have postulated immediately suggests a possible copying mechanism for the genetic material.”
Think about it: DNA needs to make copies of itself to pass along to other cells and the next generation. The nucleotides, fitting but not binding, allow the DNA to open up to be copied, like opening a book to the page you want and pressing it against a photocopier. This is basically what RNA does, by the way. If A and T always pair together, then you could take just one of the two strands and know exactly what is on the other strand. Everywhere you see an A on one, you know there is a T on the other one, even without looking at it. This would be a perfect way to synthesize new DNA.
As mentioned earlier, April 25, 1953 was the day the article explaining this structure was published. This one-page, elegant solution to the problem of heredity was the culmination of literally centuries of work. It opened the door to the information storehouse of how the body functions and what is needed to create life.
Why did it take me approximately one eternity to get to this point in the article? Why didn’t I just say that up front? Well I did say that this article had words and sentences and whatnot in it. You were warned. No backsies.
So many intuitive leaps went into each stage of the journey. The helix shape, with its intricate mosaic of nucleotides, didn’t just jump out at the first person to look under a microscope. It took multiple lines of evidence gleaned from a variety of techniques and sources over lifetimes.
Watson and Crick are credited with “discovering” the structure, but they stood on the shoulders of so many giants to accomplish this. I think there is so much to celebrate in this 1953 achievement. To me, the paper might as well be sung to the tune of the Irish folk song Rattlin’ Bog :
And in this pair there was a nucleotide A rare nucleotide, a rattlin’ nucleotide And the nucleotide in the pair And the pair in the helix And the helix in the chromosome And the chromosome in the nucleus And the nucleus in the cell And the Cell in the scientist And the scientist in the lab And the lab in the building And the building down in the valley-o
The following section, mapping the genome, takes this human pyramid of genius one step further as we make more intuitive leaps full of more big words.
Mapping the genome
At this point in our story, we as a species knew that the code for life of every species is held in their DNA. Scientists quickly began peeling apart the helix to see what nucleotides lie within, and found an amazingly long, complex chain of nucleotides. Applications for inherited diseases and cancer research were immediately apparent. Lots of information was clearly there, but it was not simply just a long stretch of ACTG. It was an alternating sequence of all four in a seemingly random pattern. Many portions of the pattern were the same in everyone, but some sections of the genome seemed to vary between individuals. It was so large and varied that it was difficult to get a systematic list of differences without a point of reference. If there was a deviation from the standard, what was the standard? Having a standard map of the genome would help to identify differences in populations (e.g., breast cancer patients vs. prostate cancer patients) and what they meant.
In 1985 a workshop to start work on just such a reference sequence was held. This was projected to take about 15 years and in the end took just under 18. The Human Genome Project, as it became called, was an international effort from the governments of several countries, and included dozens of labs and scientists. To understand what a monumental achievement this is, we need to take a step back to appreciate the extreme size of the genome.
If you unwound DNA and laid it out in a straight line, it would measure approximately two meters. Two meters of microscopic nucleotides that number just over 3 billion base pairs. Three. Billion. Even using fingers and toes, I could do about 20, max. These base pairs are distributed along 13 chromosome pairs, so even if there was a way to unravel each one all at once, it is not feasible to measure all three billion bases at once. They decided to look at a little piece at a time instead of using an approach called “Hierarchical shotgun sequencing.”
Piecing together the genetic puzzle
All types of sequencing work by chopping DNA into smaller fragments that can be read. Hierarchical sequencing works by using “restriction enzymes” that cut the DNA at specific points, with fragments being at most 800 base pairs. When you cut 3 billion base pairs into 800 chunk fragments, you wind up with a lot. I’m not sure how many; I lost count at 20, but it’s a lot. It’s hard to tell how these pieces fit together, though.
It’s like dumping out a puzzle on a table. You know you have all the pieces there, and a general idea of what your end result will look like, but it will take some time to fit all the pieces together. Not only that, but each fragment isn’t cut all at once in even cuts. There is overlap with all of them. So it’s like a puzzle where the pieces more or less fit, but some overlap. You have to set them on top of each other so they line up. Add to this the fact that a ton of the pieces all look the same because DNA repeats itself a lot. It’s like the puzzle is like a picture of a sky that is mostly blue with some clouds here and there.
The first 10 years of the project were spent identifying landmark regions. These distinct areas can act as anchor points to attach the sea of repeating fragments. Continuing our puzzle analogy, it’s like identifying the clouds so you can piece together the overlapping blue sky pieces connected to the clouds and work your way out from there. To illustrate the overlap, take a look at my diagram below.
Let’s say Read 1 is our landmark region. We know this unique section ends in a sequence of ACTG. Next, we find a fragment that matches that ATCG section so we can fit it in place. When we continue this out, we can build a continuous read made of smaller, overlapping fragments. This painstaking process was done largely by hand. Shortly after the landmark regions were identified and the process of picking up the pieces began, another privately owned company called Celera stepped in with a different approach. It used something called whole-genome shotgun sequencing.
Revolutionizing sequencing using the whole genome
Instead of relying on restriction enzymes, whole genome shotgun sequencing randomly chops the genome into fragments and relies on computer modeling to reconstruct the whole sequence. This requires an enormous amount of processing power and very sophisticated computer models to sift through the data. The amount of computing power needed would not have been possible in the late ‘80s when the project started. The late start meant that both the Human Genome Project and Celera completed their sequence at roughly the same time.
Today, the digital revolution has brought whole genome shotgun sequencing to the forefront. The ease with which one can dump an entire genome into an algorithm and get a completed, accurate sequence far surpasses the tedious Sanger Sequencing of the original project.
Completing the genome sequence
The final draft of the sequence was announced on April 14, 2003. The sequence covered roughly 92% of the genome and both systems corroborated the results. From the start, the goal of the project excluded hard-to-read areas, such as end telomeres and connection points, as well as the Y chromosome. These have later been sequenced, and gaps in the genome have been identified over the years. As they have been identified and corrected, newer versions of the sequence have been released, but the majority of it has remained unchanged. This has revolutionized our ability to identify mutations, identify causes of cancers, and, of course, help genealogists make connections.
Honoring scientific achievement and progress on DNA Day
If you have made it this far, congratulations. I award you fourteen gold stars, one for each section. It’s been a journey through incellption and back. Yes, I am milking that term for all it is worth. I hope that now when you see a double helix, you won’t just shrug it off as just a pretty shape, but recognize the countless hours of research and intuitive leaps that brought it from cork under a magnifying glass to the cultural icon and revolutionary contribution to science that we know today.
DNA Day was first celebrated in 2003 to coincide with the final release of the human genome, and April 25 was chosen as a fitting day to honor the momentous paper published on that day in 1953. To me, it celebrates the human pyramid of geniuses standing on the shoulders of geniuses to bring us to where we are now. Where do you go from here? You can explore the wonderful world of your own chromosomes with a DNA test!

About the Author
Jim brewster.
Subject Matter Expert at FamilyTreeDNA
Jim Brewster was born at a very early age and gradually became older. He has been in the genetic genealogy field since 2014 and delivered numerous presentations at genealogy conferences. He has helped with collaborations between FamilyTreeDNA and non-profit organizations and for some reason FamilyTreeDNA decided to let him write stuff too.
With a proven track record of both doing things and accomplishing stuff, Jim enjoys presenting and writing about genetic genealogy methods and the science of DNA testing. In his free time, he enjoys puns and cat pictures.
Add comment Cancel reply
Privacy preference center, privacy preferences.

From the crime scene to the courtroom: the journey of a DNA sample

Honorary Research Fellow, The University of Queensland

PostDoc Ecological and Evolutionary Genetics, The University of Queensland
Disclosure statement
The authors do not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and have disclosed no relevant affiliations beyond their academic appointment.
University of Queensland provides funding as a member of The Conversation AU.
View all partners
The O.J. Simpson murder trial in 1995 introduced DNA forensics to the public. The case collapsed, partly because the defence lawyers cast doubt on the validity of the evidence thanks to the inappropriate way the samples were handled .
Things have changed since then. There are now safeguards in place to ensure the integrity of the chain of evidence. Laboratory protocols and procedures have also advanced.
By following a piece of evidence from the crime scene to the courtroom, we’ll explain just how DNA is studied in the lab and used in the modern legal system.
Read more: Explainer: Forensic science
From the crime scene
The DNA sample’s journey begins at the crime scene.
There are several principles that guide DNA evidence collection by the crime scene examiner . In particular, the avoidance of contamination or DNA degradation, and ensuring the chain of custody.
The risk of contamination (from the collector or other evidence samples) is reduced by using sterile, disposable supplies. Degradation is minimised by drying samples before bagging.
Storing dried samples in paper bags rather than plastic, and maintaining samples at the proper temperature helps preserve the DNA and prevent microbial contamination.
It is also important to plan what to collect and how – sufficient material may be required for independent testing by the defence.

When any sample arrives in a lab, the first step is to extract the DNA.
The blood samples analysed in the O.J. Simpson trial were typical of the time when large amounts of DNA were required to conduct testing. Today, small amounts of DNA, known as trace DNA, can be analysed from items such as cigarette butts, hair follicles, saliva, semen, and even faeces .
This is possible because of the invention of a method in the 1980s called the polymerase chain reaction or “ PCR ”, which allows an individual strand of DNA to be replicated many times. This creates thousands of copies until there is enough DNA to conduct tests.
Analysis begins
The mainstay of modern DNA identification is short tandem repeat (STR) markers, which are small sections of DNA that vary by length (the number of repeats).
Multiple STR markers are used to create a DNA profile. They are tested using commercial kits that often incorporate a sex determination test (the amelogenin gene).
- Mitochondrial DNA
Another method uses mitochondrial DNA.
Mitochondrial DNA tends to last longer than other types of DNA and is often relied on in cold cases. The sequence of mitochondrial DNA “letters” is passed down from mother to child (with the exception of rare mutations), so mothers and grandmothers share the same DNA sequence as their children (but fathers do not).
This makes mitochondrial DNA useful in identifying missing persons - the bones of Daniel Morcombe were identified this way .
Read more Ned Kelly remains are positively identified … but how was it done?
The Y chromosome
The Y chromosome is present only in males and is passed from father to son. This makes Y chromosome STR markers a useful tool in situations such as sexual assault cases where male and female DNA samples might be mixed and the male suspect’s identity needs to be established.
In the same way as mitochondrial markers, Y-markers can be used for identification through family matching. The process of familial matching in criminal investigations raises privacy concerns but is increasingly commonplace.
In one recent incident, it was suggested that the surname of a suspect was identified from records of male family members in public genetic ancestry databases.

DNA databases and sample matching
Australian law enforcement uses the National Criminal Investigation DNA Database ( NCIDD ), which is managed by the Australian Criminal Intelligence Commission.
The more records added to the database, the greater the odds of making an accidental match. This is because the number of potential matches increases.
To reduce the risk of false “hits”, genetic profiles can be made more complex. Increasing the number of STRs in each profile reduces the risk of a spurious match because the probability of a match (at 20 markers, for example) is estimated by multiplying the probabilities of each STR marker.
The Australian system originally used nine STR’s and a sex-determination gene. In 2013 this was increased to 18 core markers .
Internationally, there are moves towards a standard set of 24 markers (such as GlobalFiler ). With this many markers, the odds of two people having the same profile (twins excepted) are incredibly small. This makes an STR profile a powerful way to exclude suspects as well as making matches.
In the courtroom
Modern DNA forensic methods are powerful and sensitive, but great care must be taken to prevent miscarriages of justice.
It is difficult for people to comprehend probabilities like one in a quadrillion, and the presentation of such numbers in court can become prejudicial.
In the case of Aytugrul v the Queen , DNA evidence was presented as an exclusion percentage of 99.9, and the defence argued that this would indicate certainty of guilt to the jury.
Although the High Court of Australia ultimately allowed the DNA evidence presentation in Aytugrul v the Queen , survey data suggest that the statistical presentation of genetic evidence may affect how it is understood and used by a jury .
Such issues have lead to guidelines by the US Department of Justice, among other justice groups, for the language used in forensic testimony and reports.
There’s also a risk that contamination might implicate an innocent person. For that reason, DNA evidence is best used in support of other types of evidence.
In the case of R v Jama , DNA evidence was the sole basis of the rape case. Only after 16 months’ imprisonment was it revealed that the sample taken by the doctor was probably contaminated.

Forensics in the future
DNA forensics will continue to evolve.
Take a genetic test that can predict eye and hair colour : this test examines (or “genotypes”) 24 single letter DNA variants. These are analysed with a statistical model that provides probabilities for hair and eye colour based on a large database that links DNA variants to appearance.
Understanding how DNA is linked to facial features has even led to the creation of DNA-based mugshots .
“Massively parallel” sequencing machines are also a significant advance. These can turn the approximately 3.2 billion DNA “letters” of the human genome into digital information in a matter of hours.
This opens up all of the information contained in our genetic code to law enforcement. For example, some researchers claim it’s possible to predict the age of a suspect from a blood sample within a mean error margin of 3.8 years, based on methylation markers in the DNA, and this may be improved with the assistance of machine learning .
The more we understand the link between appearance and DNA, the better its predictive power will be. It’s tempting to speculate how the O.J. Simpson trial may have turned out with modern forensic DNA protocols and technology.
- Y chromosome
- Polymerase chain reaction
- Technology explainer
Project Offier - Diversity & Inclusion
Senior Lecturer - Earth System Science
Sydney Horizon Educators (Identified)
Deputy Social Media Producer
Associate Professor, Occupational Therapy
- Computers & Technology
- Computer Science
Enjoy fast, free delivery, exclusive deals, and award-winning movies & TV shows with Prime Try Prime and start saving today with fast, free delivery
Amazon Prime includes:
Fast, FREE Delivery is available to Prime members. To join, select "Try Amazon Prime and start saving today with Fast, FREE Delivery" below the Add to Cart button.
- Cardmembers earn 5% Back at Amazon.com with a Prime Credit Card.
- Unlimited Free Two-Day Delivery
- Streaming of thousands of movies and TV shows with limited ads on Prime Video.
- A Kindle book to borrow for free each month - with no due dates
- Listen to over 2 million songs and hundreds of playlists
- Unlimited photo storage with anywhere access
Important: Your credit card will NOT be charged when you start your free trial or if you cancel during the trial period. If you're happy with Amazon Prime, do nothing. At the end of the free trial, your membership will automatically upgrade to a monthly membership.
Buy new: $23.43 $23.43 FREE delivery Thursday, May 2 on orders shipped by Amazon over $35 Ships from: Amazon.com Sold by: Amazon.com
Return this item for free.
Free returns are available for the shipping address you chose. You can return the item for any reason in new and unused condition: no shipping charges
- Go to your orders and start the return
- Select the return method
Buy used: $18.04
Download the free Kindle app and start reading Kindle books instantly on your smartphone, tablet, or computer - no Kindle device required .
Read instantly on your browser with Kindle for Web.
Using your mobile phone camera - scan the code below and download the Kindle app.

Image Unavailable

- To view this video download Flash Player
Follow the author

The Amazing Journey of Reason: from DNA to Artificial Intelligence (SpringerBriefs in Computer Science) 1st ed. 2020 Edition
Purchase options and add-ons.
- ISBN-10 3030259617
- ISBN-13 978-3030259617
- Edition 1st ed. 2020
- Publication date December 7, 2019
- Part of series SpringerBriefs in Computer Science
- Language English
- Dimensions 6.1 x 0.3 x 9.25 inches
- Print length 132 pages
- See all details

Editorial Reviews
From the back cover, about the author, product details.
- Publisher : Springer; 1st ed. 2020 edition (December 7, 2019)
- Language : English
- Paperback : 132 pages
- ISBN-10 : 3030259617
- ISBN-13 : 978-3030259617
- Item Weight : 6.9 ounces
- Dimensions : 6.1 x 0.3 x 9.25 inches
- #172 in Electronic Data Interchange (EDI)
- #450 in Computer Algorithms
- #636 in Internet & Networking Computer Hardware
About the author
Mario alemi.
Mario Alemi (1970- ) is a physicist and author. He is the author of "The Amazing Journey of Reason from DNA to Artificial Intelligence". Alemi writes about how Homo sapiens, after having reached a limit in the development of the brain, developed communication skills –shifting in this way information storage and processing from the individual to the network of people. According to this view, the emergence of digital communication (the "social nervous system") is an inevitable process, not different to the emergence of the nervous system in complex organisms or DNA in biological cells.
Alemi studied high energy physics in Milan, Italy and Marburg, Germany. Worked on his PhD at CERN, Geneva, Switzerland. He holds a postgraduate degree in International Journalism from City University, London, UK, where he lived for many years.
Customer reviews
Customer Reviews, including Product Star Ratings help customers to learn more about the product and decide whether it is the right product for them.
To calculate the overall star rating and percentage breakdown by star, we don’t use a simple average. Instead, our system considers things like how recent a review is and if the reviewer bought the item on Amazon. It also analyzed reviews to verify trustworthiness.
- Sort reviews by Top reviews Most recent Top reviews
Top reviews from the United States
There was a problem filtering reviews right now. please try again later..

- Amazon Newsletter
- About Amazon
- Accessibility
- Sustainability
- Press Center
- Investor Relations
- Amazon Devices
- Amazon Science
- Sell on Amazon
- Sell apps on Amazon
- Supply to Amazon
- Protect & Build Your Brand
- Become an Affiliate
- Become a Delivery Driver
- Start a Package Delivery Business
- Advertise Your Products
- Self-Publish with Us
- Become an Amazon Hub Partner
- › See More Ways to Make Money
- Amazon Visa
- Amazon Store Card
- Amazon Secured Card
- Amazon Business Card
- Shop with Points
- Credit Card Marketplace
- Reload Your Balance
- Amazon Currency Converter
- Your Account
- Your Orders
- Shipping Rates & Policies
- Amazon Prime
- Returns & Replacements
- Manage Your Content and Devices
- Recalls and Product Safety Alerts
- Conditions of Use
- Privacy Notice
- Consumer Health Data Privacy Disclosure
- Your Ads Privacy Choices
How to Activate Your Ancient DNA, Shed Your Old Identity and Heal Yourself with Frank Elaridi The Spiritual Hustler
“Life's like a dance with destiny. We think we choose, but really, there's a bigger plan at play. My journey from journalism to podcasting showed me that forcing things only leads to feeling out of place. Trying to fit into two worlds taught me that true recognition comes from embracing who you really are.” - Fran Elaridi
- Episode Website
- More Episodes
- © 2024, Jessica Zweig, Inc.
More by SoulFire Productions
- Share full article
For more audio journalism and storytelling, download New York Times Audio , a new iOS app available for news subscribers.

- April 25, 2024 • 40:33 The Crackdown on Student Protesters
- April 24, 2024 • 32:18 Is $60 Billion Enough to Save Ukraine?
- April 23, 2024 • 30:30 A Salacious Conspiracy or Just 34 Pieces of Paper?
- April 22, 2024 • 24:30 The Evolving Danger of the New Bird Flu
- April 19, 2024 • 30:42 The Supreme Court Takes Up Homelessness
- April 18, 2024 • 30:07 The Opening Days of Trump’s First Criminal Trial
- April 17, 2024 • 24:52 Are ‘Forever Chemicals’ a Forever Problem?
- April 16, 2024 • 29:29 A.I.’s Original Sin
- April 15, 2024 • 24:07 Iran’s Unprecedented Attack on Israel
- April 14, 2024 • 46:17 The Sunday Read: ‘What I Saw Working at The National Enquirer During Donald Trump’s Rise’
- April 12, 2024 • 34:23 How One Family Lost $900,000 in a Timeshare Scam
- April 11, 2024 • 28:39 The Staggering Success of Trump’s Trial Delay Tactics
The Crackdown on Student Protesters
Columbia university is at the center of a growing showdown over the war in gaza and the limits of free speech..
Hosted by Michael Barbaro
Featuring Nicholas Fandos
Produced by Sydney Harper , Asthaa Chaturvedi , Olivia Natt , Nina Feldman and Summer Thomad
With Michael Simon Johnson
Edited by Devon Taylor and Lisa Chow
Original music by Marion Lozano and Dan Powell
Engineered by Chris Wood
Listen and follow The Daily Apple Podcasts | Spotify | Amazon Music
Columbia University has become the epicenter of a growing showdown between student protesters, college administrators and Congress over the war in Gaza and the limits of free speech.
Nicholas Fandos, who covers New York politics and government for The Times, walks us through the intense week at the university. And Isabella Ramírez, the editor in chief of Columbia’s undergraduate newspaper, explains what it has all looked like to a student on campus.
On today’s episode
Nicholas Fandos , who covers New York politics and government for The New York Times
Isabella Ramírez , editor in chief of The Columbia Daily Spectator

Background reading
Inside the week that shook Columbia University .
The protests at the university continued after more than 100 arrests.
There are a lot of ways to listen to The Daily. Here’s how.
We aim to make transcripts available the next workday after an episode’s publication. You can find them at the top of the page.
Research help by Susan Lee .
The Daily is made by Rachel Quester, Lynsea Garrison, Clare Toeniskoetter, Paige Cowett, Michael Simon Johnson, Brad Fisher, Chris Wood, Jessica Cheung, Stella Tan, Alexandra Leigh Young, Lisa Chow, Eric Krupke, Marc Georges, Luke Vander Ploeg, M.J. Davis Lin, Dan Powell, Sydney Harper, Mike Benoist, Liz O. Baylen, Asthaa Chaturvedi, Rachelle Bonja, Diana Nguyen, Marion Lozano, Corey Schreppel, Rob Szypko, Elisheba Ittoop, Mooj Zadie, Patricia Willens, Rowan Niemisto, Jody Becker, Rikki Novetsky, John Ketchum, Nina Feldman, Will Reid, Carlos Prieto, Ben Calhoun, Susan Lee, Lexie Diao, Mary Wilson, Alex Stern, Dan Farrell, Sophia Lanman, Shannon Lin, Diane Wong, Devon Taylor, Alyssa Moxley, Summer Thomad, Olivia Natt, Daniel Ramirez and Brendan Klinkenberg.
Our theme music is by Jim Brunberg and Ben Landsverk of Wonderly. Special thanks to Sam Dolnick, Paula Szuchman, Lisa Tobin, Larissa Anderson, Julia Simon, Sofia Milan, Mahima Chablani, Elizabeth Davis-Moorer, Jeffrey Miranda, Renan Borelli, Maddy Masiello, Isabella Anderson and Nina Lassam.
Nicholas Fandos is a Times reporter covering New York politics and government. More about Nicholas Fandos
Advertisement
IMAGES
VIDEO
COMMENTS
DNA: a timeline of discoveries - BBC Science Focus Magazine
Freddie Flintoff and Jamie Redknapp explore their past in DNA Journey.(Image credit: ITV) TV presenting duo Ant and Dec teamed up to explore their family trees in February 2020 on ITV's two-part documentary Ant and Dec's DNA Journey . Now three more pairs of celebrities are setting off on their own genealogical adventures in a new three-part ...
Encoded within this DNA are the directions for traits as diverse as the color of a person's eyes, the scent of a rose, and the way in which bacteria infect a lung cell. DNA is found in nearly all ...
DNA Journey release date. DNA Journey season 2 is a three-parter on ITV that begins Tuesday, April 5 at 9pm and runs at the same time on ITV in subsequent weeks — see our episode guide below for details. It will also become available on ITV Hub. The first episode features The Chase stars Anne Hegerty and Shaun Wallace, followed by Rula Lenska and Maureen Lipman, then Torvill and Dean.
Published Thu 10 Mar 2022. Factual. Download release. DNA Journey r eturns to ITV and ITV Hub next month, as the first of our seven celebrity duos set off on a quest to discover where they come ...
DNA Journey has shared a first official look at its new series lineup, including Strictly Come Dancing and Line of Duty stars. The ITV show, which spun out of a two-part special with Ant & Dec ...
Hugh Bonneville, John Bishop, Adrian Dunbar, Neil Morrisey, Alex Brooker, Johnny Vegas and Oti and Motsi Mabuse to take part in the new series of DNA Journey on ITV1 and ITVX later this year.
The DNA Journey is part of momondo's overall vision of a more open and tolerant world. You can read more about momondo's vision and ongoing activities here: letsopenourworld.com. How were the participants found? As is the case with many campaign films, we employed casting agencies to help us find participants. Specifically, we used two ...
To celebrate diversity in the world we asked 67 people from all over the world to take a DNA test. It turns out that they have much more in common with other...
The international research project could be described as the greatest journey ever made - albeit an inwards one. Scientists had achieved a high-quality sequence of the entire human genome. ... 2013 - DNA Worldwide and Eurofins Forensic discover identical twins have differences in their genetic makeup.
DNA Journey. S. Documentaries & Lifestyle. 1h 30m. Famous faces bond over their remarkable family secrets in this exploratory documentary. Watch them find relatives they never knew existed. More ...
The journey to understand previously unknown microbial genes. The analysis of DNA sequences sheds light on microbial biology, but it is difficult to assess the function of genes that have little ...
The Journey of Man: A Genetic Odyssey is a 2002 book by Spencer Wells, an American geneticist and anthropologist, in which he uses techniques and theories of genetics and evolutionary biology to trace the geographical dispersal of early human migrations out of Africa. The book was made into a TV documentary in 2003. ... (Haplogroup CT (Y-DNA)).
Learn more about AncestryDNA: http://ancestry.com/s55735/t32468/rd.ashx. Ancestry is proud to work with momondo's DNA Journey to help show the world that the...
We asked 67 people from all over the world to take a DNA test. It turns out they have much more in common with other nationalities than they thought ...It's ...
DNA, the repository of all genetic traits of a human, is present in all nucleated cells except red blood cells in the form of a double helix structure tightly bound with histone proteins in chromosomes. DNA is unchangeable from cell to cell within an individual and contains all the genetic information necessary (6, 7).
DNA Day celebrates this achievement, but to me, what it really celebrates is the monumental advances in science that brought us the understanding we have today of the fundamental building blocks of life. ... This journey has it all: words, punctuation, and even the occasional picture! Unveiling the microscopic world and the discovery of the ...
The DNA sample's journey begins at the crime scene. There are several principles that guide DNA evidence collection by the crime scene examiner. In particular, the avoidance of contamination or ...
The integrity of DNA is constantly under threat by many genotoxic agents both within and outside the cell. It is estimated that the DNA in a typical mammalian cell is exposed to 10 4 to 10 5 lesions every day in the form of altered bases, abasic sites, inter- or intrastrand crosslinks, bulky adducts, mismatches and small insertions and deletions, and single- or double-strand breaks [1].
He is the author of "The Amazing Journey of Reason from DNA to Artificial Intelligence". Alemi writes about how Homo sapiens, after having reached a limit in the development of the brain, developed communication skills -shifting in this way information storage and processing from the individual to the network of people. According to this view ...
The central dogma of molecular biology outlines the flow of genetic information from DNA to RNA to proteins. With a limited vocabulary of four nucleotides (A, C, G, and T), DNA encodes an extensive instruction set, including the chromosomal positions where RNAs begin to be transcribed and the magnitudes of their expression.
"Life's like a dance with destiny. We think we choose, but really, there's a bigger plan at play. My journey from journalism to podcasting showed me that forcing things only leads to feeling out of place. Trying to fit into two worlds taught me that true recognition comes from embracing who you really are." - Fran Elaridi
The Crackdown on Student Protesters Columbia University is at the center of a growing showdown over the war in Gaza and the limits of free speech.
_wealthyy888 on April 24, 2024: "My Real DNA. . . . "Self-improvement is a lifelong journey. Embrace the challenges, celebrate the victories, and keep moving forward ...
Community is part of social work program's DNA. April 16, 2024. Faculty member selected for Faculty Innovation Fellows Program ... The healing power of poetry. April 15, 2024. Following water's journey through a hand of cards. April 12, 2024. View News Home. 1200 S. Franklin St. Mount Pleasant, Mich. 48859 989-774-4000. Faculty & Staff ...
But limiting Sagar group's work to just that would be unfair, certainly to the newer generation of Sagars, who are spearheading a new wave of storytelling and filmmaking. Akash Sagar, the CEO of Sagar Pictures Entertainment, and the grandson of Ramanand Sagar, spoke to DNA recently about his journey as well as the journey of the company.